06-Kubernetes 实战指导
Kubernetes 实战指导(更新中)
本文以一个简单 Go 应用为例,演示如何一步步在生产环境中使用 Kubernetes。
1. 部署一个完整的应用
1.1 编写一个简单的 Go 应用
这个 Go 应用的逻辑很简单,它是一个支持从配置动态加载路由的 HTTP 服务器。初始化此应用:
go mod init k8s_action
go mod tidy1.2 使用 ConfigMap 存储配置
传统方式下,我们通常将配置文件存储在单独文件中,并通过环境变量或者命令行参数传递给应用。
在 K8s 环境中,我们需要将配置迁移到 ConfigMap 中,并通过环境变量或者卷挂载的方式传递给应用。
注意将 K8s 清单放在一个单独的目录(如base_manifest)下,以便后续批量部署。
虽然可以在 Dockerfile 中直接将配置文件打包到容器,但这种方式通常伴随的是将配置文件存储在代码库中,这并不符合 K8s 的最佳实践。 同时也不适合用来存储重要配置。
如果有重要的配置,比如证书私钥或 Token 之类的敏感信息,请使用 Secret 来存储。
1.3 使用 Secret 存储敏感信息
通常一个后端应用会链接到数据库来对外提供 API 服务,所以我们需要为应用提供数据库密码。
虽然 ConfigMap 也可以存储数据,但 Secret 更适合存储敏感信息。在 K8s 中,Secret 用来存储敏感信息,比如密码、Token 等。
1.3.1 加密存储 Secret 中的数据
虽然 Secret 声称用来存储敏感信息,但默认情况下它是非加密地存储在集群存储(etcd)上的。 任何拥有 API 访问权限的人都可以检索或修改 Secret。
请参考以下链接来加密存储 Secret 中的数据:
1.4 使用 Dockerfile 打包应用
这一步中,我们编写一个 Dockerfile 文件将 Go 应用打包到一个镜像中,以便后续部署为容器。
注意在 Dockerfile 中定制你的 Go 版本。
1.5 准备镜像仓库
为了方便后续部署,我们需要将打包好的镜像上传到镜像仓库中。
作为演示,本文使用 Docker Hub 作为镜像仓库。但在生产环境中,为了应用安全以及提高镜像拉取速度,我们应该使用(搭建)私有的仓库。
常用的开源镜像仓库有 Docker Registry 和 Harbor。如果你使用云厂商的托管集群,可以使用它们提供的镜像仓库产品。
1.6 编写 Deployment 模板
Deployment 是 K8s 中最常用的用来部署和管理应用的资源对象。它支持应用的多副本部署以及故障自愈能力。
你可以在模板中定制应用的副本数量、资源限制、环境变量等配置。
[!NOTE] 你可能看情况需要修改模板中的
namespace,生产环境不建议使用 default 命名空间。因为这不利于对不同类型的应用进行隔离和资源限制。 比如,你可以为后端服务和前端服务分别使用 backend 和 frontend 命名空间。
为镜像指定指纹
docker 拉取镜像时支持使用如下命令:
docker pull busybox:1.36.1@sha256:7108255e7587de598006abe3718f950f2dca232f549e9597705d26b89b7e7199
# docker images --digests 获取镜像hash后面的sha256:710...是镜像的唯一 hash。当有人再次推送相同 tag 的镜像覆盖了旧镜像时,拉取校验就会失败,这样可以避免版本管理混乱导致的部署事故。
所以我们可以在 Deployment 模板中指定镜像的 tag 的同时使用@sha256:...来指定镜像的 hash 以提高部署安全性。
1.7 使用 CI/CD 流水线
完成前述步骤后,应该得到以下文件布局:
├── Dockerfile
├── go.mod
├── go.sum
├── base_manifest
│ ├── configmap.yaml
│ ├── deployment.yaml
│ └── secret.yaml
└── main_multiroute.go现在可以将它们提交到代码仓库中。然后使用 CI/CD 流水线来构建镜像并部署应用。
代码库中通常会存储*非生产环境的配置文件,对于生产环境使用的配置文件(ConfigMap 和 Secret),不应放在代码库中, 而是以手动方式提前部署到环境中。
参考下面的指令来配置 CI/CD 流水线:
# 假设现在已经进入到构建机(需要连接到k8s集群)
IMAGE=leigg/go_multiroute
TAG=v1 # 每次迭代时手动指定
_IMAGE_=$IMAGE:$TAG
# 构建镜像(将leigg替换为你的镜像仓库地址)
docker build --build-arg CODE_SRC=go_multiroute . -t $_IMAGE_
# 推送镜像到仓库
$ docker push $_IMAGE_
The push refers to repository [docker.io/leigg/go_multiroute]
f658e2d998f1: Pushed
06d92acd05c8: Pushed
3ce819cc4970: Mounted from library/alpine
v1: digest: sha256:74bf6d94ea9af3e700dfd9fe64e1cc6a04cd75fb792d994c63bbc6d69de9b7ee size: 950
# 部署应用
$ kubectl apply -f ./base_manifest
# 更新应用
$ kubectl set image deployment/go-multiroute go-multiroute=$_IMAGE_查看应用部署情况:
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
go-multiroute 2/2 2 2 7s
$ kubectl get po
NAME READY STATUS RESTARTS AGE
go-multiroute-f4f8b64f4-564qq 1/1 Running 0 8s
go-multiroute-f4f8b64f4-v64l6 1/1 Running 0 8s这里使用的是简单的滚动更新策略进行部署更新应用,实际环境中你可能会根据应用情况而使用蓝绿部署或金丝雀部署, 这部分将在本文的5.8 部署策略中进行详细讨论。
1.8 为服务配置外部访问
现在已经在集群内部部署好了应用,但是还无法从集群外部访问。我们需要再部署以下资源来提供外部访问能力。
- Service:为服务访问提供流量的负载均衡能力(支持 TCP/UDP/SCTP 协议)
- Ingress:管理集群外部访问应用的路由端点,支持 HTTP/HTTPS 协议
- Ingress 需要安装某一种 Ingress 控制器才能正常工作,常用的有 Nginx、Traefik。
清单提供:
部署 Ingress 控制器的步骤这里不再赘述,请参考 基础教程。
下面是部署 Service 和 Ingress 的步骤:
$ kubectl apply -f ./expose_manifest
ingress.networking.k8s.io/go-multiroute created
service/go-multiroute created
# 注意:service/kubernetes是默认创建的,不用理会
$ kubectl get svc,ingress
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/go-multiroute ClusterIP 10.96.219.33 <none> 3000/TCP 19s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/go-multiroute nginx * 80 19s现在,可以通过 Ingress 控制器开放的端口来访问应用了。笔者环境安装的 Nginx Ingress 控制器,查看其开放的端口:
# PORT(S) 部分是Nginx Ingress控制器内对外的端口映射
# 内部80端口映射到外部 30073,内部443端口映射到外部30220
kubectl get svc -ningress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.171.227 <pending> 80:30073/TCP,443:30220/TCP 3m46s
ingress-nginx-controller-admission ClusterIP 10.96.7.58 <none> 443/TCP 3m46s使用控制器的端口访问服务:
# 在任意节点上进行访问
$ curl 127.0.0.1:30073/route1
[v1] Hello, You are at /route1, Got: route1's content
# /route2 尚未在ingress的规则中定义,所以不能通过ingress访问
$ curl 127.0.0.1:30073/route2
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>OK,现在访问没有问题了。
1.8.1 为什么通过 30073 端口访问
Nginx Ingress 控制器默认通过 NodePort 方式部署,所以会在宿主机上开放两个端口(本例中是 30073 和 30220), 这两个端口会分别代理到 Ingress 控制器内部的 80 和 443 端口。
本例中部署的 Go 应用是一个后端服务,对于向外暴露的端口号没有要求。 但如果是一个前端应用,比如是一个 Web 网站,那么可能就有对外暴露 80/443 端口的要求。 此时就需要调整 Ingress 控制器部署方式,使用 LoadBalancer 或HostNetwork方式部署。
1.9 更新配置的最佳实践
应用上线后,我们可能会有更改应用配置的需求。一般的做法是直接更新现有的 ConfigMap,然后重启所有 Pod。 但这不是 K8s 的最佳实践。原因有以下几个:
- 更新 ConfigMap 不会触发 Deployment 中所有 Pod 重启
- 若更新后的配置有问题不能迅速回滚(需要再次编辑现有 ConfigMap),导致服务短暂宕机
而最佳实践是为 ConfigMap 命名带上版本号如app-config-v1,然后部署新版本的 ConfigMap, 再修改 Deployment 模板中引用的 ConfigMap 名称,最后更新 Deployment(触发所有 Pod 滚动更新)。
当需要回滚时,再次更新 Deployment 即可。
2. 开发者工作流
为了提高开发人员的工作效率和最大化在日常工作中模拟在生产环境中开发,我们通常会搭建一个开发集群来提供给开发者们完成日常开发。 但随之而来的就是集群的用户管理、资源额度限制以及回收工作,我们可以开发脚本来自动化完成这些工作。
2.1 搭建不同环境的集群
开发集群
我们需要一个共享 K8s 集群来提供给开发者们使用,他们的日常开发流程包括 PR 提交、代码 review、构建、部署等工作都将和生产环境保持基本一致。
但我们必须为每个开发者分配单独的 K8s 命名空间,然后设置资源额度限制,防止开发者们无节制地使用集群资源以造成互相干扰。 当团队规模较大时,建议为 10~20 人共享一个集群,而不是上百人共享一个超大集群,这样可以简化集群的管理工作。
测试环境
当开发者在开发环境完整测试过自己提交的代码后,就可以考虑部署到测试环境,并告知测试人员进行测试。 测试环境通常只有一个 K8s 集群由所有人共享。
预发布环境
大部分公司都会有一个预发布环境,用来部署一些需要经过测试环境验证的应用版本,比如一些新功能或一些需要修复的 bug。 这个环境应该与生产环境尽可能保持高度一致,包括节点数量、网络等其他配置,且相对测试环境具有更严格的权限控制。 不允许开发者随意更改数据库等配置,测试人员在预发布环境应按照生产环境的标准进行测试。
镜像仓库
镜像仓库是用来存放应用镜像的地方,通常由运维人员来维护。每个环境都应该有一个本地的镜像仓库,以加快应用部署。
2.2 管理员使用的脚本
为了简化集群的用户管理、资源额度限制以及回收工作,我们可以开发一些脚本来协助管理员轻松完成这些工作。
- new_user.sh:在集群中添加一个新用户,并创建相应的命名空间、角色和额度限制。
- 此脚本会同时生成
client-cert-$USER.crt和client-cert-$USER.key
- 此脚本会同时生成
- del_user.sh:删除集群中的一个用户命名空间(包含空间下的所有资源)。
- setup_kubeconfig.sh:初始化用户使用的 kubeconfig 文件。
- 此脚本会在执行目录下生成
dev-config文件,将此文件分发给对应开发人员作为 kubeconfig 文件即可。
- 此脚本会在执行目录下生成
笔者在脚本中添加了详实的注释,你可以阅读它们来了解脚本用法和步骤含义。
2.3 更方便的查询应用日志
应用上线后,我们通常会有查看应用日志的需求。 默认的应用日志分散存储在每个 Pod 所在节点的/var/log/pods目录,且它们会伴随 Pod 的消失而被删除。 这不利用开发者们查看日志的需求,因此我们需要一个中心化存储日志的方案。 请参考Kubernetes 日志收集来了解如何搭建日志收集系统。
如果因为某些原因不希望搭建日志收集系统(或者说是偷懒~), 你也可以通过修改每个节点上的 kubelet 配置来调整容器日志的存储大小和文件数量,具体步骤也请参考Kubernetes 日志收集中的 业务容器日志。 其次,你还可以参考Kubernetes 维护指导中的日志查看来使用第三方工具来高效查询容器日志。
[!NOTE] 除了 Pod 日志,我们还需要关注集群组件日志、节点日志、集群审计日志。
2.4 启动开发
开发过程中,开发者需要频繁地构建并推送镜像、更新应用、查看应用日志。 这其中最为重要的步骤就是镜像 tag 定义以及更新应用的操作。
镜像 tag 使用版本化语义而不是 latest
在构建用于开发环境的自测试镜像时,对于镜像 tag,开发者最好是使用版本化语义而不是latest。 使用latest可以免去每次构建镜像时都需要手动修改 tag 的麻烦,但同时也带来了不确定性。 因为你无法完全确定所更新的应用使用了你刚刚构建并推送的镜像。倘若你将误以为自测成功的代码发布到了生产环境, 难以想象将会发生的事情和面临的后果😑。
更新应用
在使用版本化语义的镜像 tag 后,我们可以更从容的使用kubectl set image...命令来更新应用。 注意,在开发以及后续的上线过程中,我们都不需要修改代码库中的 Deployment YAML 文件。
2.5 使用第三方工具为开发提效
2.5.1 IDE 插件
编写此文时已经是 2024 年了,主流的 VSCode 和 Jetbrains 家族 IDE 都已经有大量的 Kubernetes 插件可用, 这些插件可以帮助开发者通过图形化的方式与开发环境的 K8s 集群进行便捷交互,免去手动输入 kubectl 命令的繁琐。
2.5.2 K9s 终端面板
K9s 是一个终端形式的 K8s 资源面板,它支持在终端中以可视化方式查看和管理 Kubernetes 集群中的资源,包括 Pod、Deployment、Service 等。 它支持以方向键、回车键和空格键与面板交互,免去手敲命令的麻烦。
我们可以在测试环境和预发布环境(也包括生产环境)安装 K9s,这样可以更便捷的查看应用状态、日志、事件、以及进入 Pod 内的容器 Shell,极大地改善了 K8s 的使用体验。
2.5.3 开源 K8s 日志工具
常规查看容器日志的命令是kubectl logs,但这个命令有一些局限性,比如:
- 一次只能查看一个 Pod 的日志(若不使用
-l的话) - 不能指定 Deployment、Service、Job、Stateful 和 Ingress 名称进行日志查看
- 不能查看指定节点上的所有 Pod 日志
- 不支持颜色打印
等等。你可以使用开源的 K8s Pod 日志查看工具来提高效率,具体可以参考 Kubernetes 维护指导 中的日志查看小节。
2.5.4 K8s 资源清单风险分析工具
或许在较小的集群中或者是不那么重要的业务中,我们并不会去特别注意 K8s 资源清单的编写规范,例如对容器的 CPU/内存限制、设置容器安全上下文等。 但我们需要知道,Pod 中的容器是本质上来说还是运行在集群节点上的,不安全的资源清单可能会导致容器在节点上被恶意利用,从而导致集群被攻击。
好在已经有不少开源工具可以协助我们轻松完成资源清单的修复工作,这里推荐以下几个工具:
你可以将这些工具中的一个或几个添加 CI/CD 流水线中,以在每次提交代码时自动检查资源清单的安全性。
3. 采集集群指标
3.1 简介
指标是指针对某一种资源在一段时间内的使用情况的统计,例如 CPU 使用率、内存使用量、网络带宽、磁盘使用量等。
指标采集通常有两种说法,即黑盒监控和白盒监控。黑盒监控是从集群的外部视角采集数据。多用于传统的 CPU、内存、磁盘等硬件资源的监控, 非常适用于对基础设施的监控。而白盒监控更关注应用程序的状态细节,比如 HTTP 请求总数、500 错误请求数和请求延迟等。 白盒监控让我们知道系统为什么处于当前状态,让故障定位进一步有迹可循。
3.2 两种监控模式
它们分别是 USE 和 RED 模式。
3.2.1 USE 模式
USE 的释义如下:
- U——Utilization(利用率)
- S——Saturation(饱和度)
- E——Errors(错误率)
这种模式专注于基础设施监控,对应黑盒监控。
3.2.2 RED 模式
RED 的释义如下:
- R——Rate(每秒接受的请求数)
- E——Error(每秒失败的请求数)
- D——Duration(每个请求的耗时)
这种模式专注于应用程序监控,对应白盒监控。
3.3 采集目标
了解了上面的监控模式后,现在我们需要知道应该在集群中进行指标采集的目标有哪些。 这里笔者将它们分类列出:
- 控制平面:API Server、etcd、Scheduler、Controller Manager
- 工作节点:kubelet、容器运行时、kube-proxy、kube-dns 和 Pod
上面除了工作节点的 Pod 以外,其他可以归类为基础设施组件。我们需要监控这些组件暴露的各项指标并及时做出响应, 才能确保集群的稳定运行。
3.4 采集架构
3.4.1 使用 Prometheus 作为存储后端
Prometheus 是 CNCF(云原生计算基金会)中排名仅次于 Kubernetes 的一个重量级开源项目,是一个用于监控和告警的开源系统。 它提供了一个灵活的查询语言叫做PromQL,让我们可以方便地查询和分析监控数据。目前,Prometheus 已经是业界公认的监控事实标准。
Prometheus 架构图如下 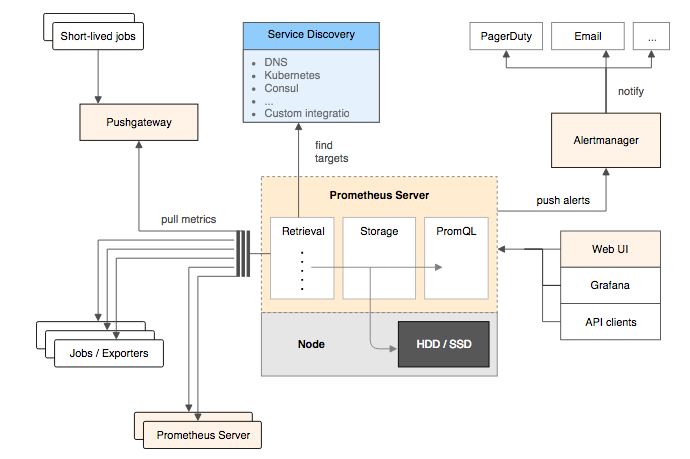
简单来说,Prometheus 由以下几个部分组成:
- Prometheus Server:负责数据采集和存储,并提供 PromQL 查询语言的支持。
- Push Gateway:支持临时性任务的数据采集。
- Exporter:用于暴露被监控组件的数据接口。
- 对于不同的采集目标(例如主机节点)需要部署对应的 Exporter,然后配置 Prometheus 主动采集即可。
- 常见的有:node_exporter、blackbox_exporter、mysqld_exporter、redis_exporter 等。
- Client Library:客户端库,为需要监控的组件提供方便的接入方式。
- 对于那些没有 Exporter 的采集目标(比如业务应用),我们可以通过客户端库自行上报数据到 Prometheus Server 中。
- Alert-manager:负责接收 Prometheus 的告警信息,并决定如何对告警进行处理,如发送邮件、短信、调用 Webhook 等。
通过上面的架构图和文字说明,我们可以了解到 Prometheus 支持以推/拉的方式采集各种目标提供的指标数据。
3.4.2 Prometheus 四种指标类型
Prometheus 中的指标可以分为以下四种类型:
- Counter(计数器)
- 简介:Counter 是一个累加器,只能增加,不能减少。通常用于表示累积的事件计数,比如请求总数、错误总数等。
- 典型用法:记录事件的总数量,例如 HTTP 请求总数、错误数量、任务完成次数等。
- 示例:http_requests_total, errors_total, tasks_completed_total。
- Gauge(仪表盘)
- 简介:Gauge 是一个可变化的数值,可以增加也可以减少。用于表示可变的度量,如温度、内存使用率等。
- 典型用法:跟踪随时间变化的指标,例如 CPU 使用率、内存占用量、连接数等。
- 示例:cpu_usage, memory_usage, active_connections.
- Histogram(直方图)
- 简介:Histogram 统计和存储数据的分布情况,如请求响应时间的分布。
- 典型用法:衡量持续时间或值的分布情况,例如请求响应时间、API 调用耗时等。
- 示例:http_request_duration_seconds.
- Summary(摘要)
- 简介:Summary 也用于记录持续时间数据,但它提供的是可变精度的摘要,而不是固定数量的桶。
- 典型用法:与 Histogram 类似,用于记录持续时间,但通常用于更复杂的分布情况,比如 p50、p90、p99 等分位数。
- 示例:api_request_duration_seconds_summary.
这四种指标类型几乎覆盖所有场景,并且每种类型都提供了丰富的标签(label)用于描述指标的维度信息。 我们只需要在推/拉数据时指定需要采集的指标类型和标签,Prometheus 就能自动进行数据采集和存储。
3.4.3 使用 Grafana 作为可视化组件
Prometheus 本质上只是一个时序数据库,它本身并不具备强大的可视化能力。要想将采集到的指标数据进行丰富的可视化展示, 我们需要使用一个可视化组件,它就是 Grafana。Prometheus+Grafana 是一个常见的兄弟组合,几乎不会分开使用。
Grafana 是一个开源的度量分析和可视化平台,它可以通过将时序数据导入其中而建立一个数据仪表盘。想象一下, 你只需要通过一个网页上的数据大盘就能对整个集群(包括几十上百甚至更多的节点)的运行状态了如指掌,这该是多么酷的一件事情。
当然这个兄弟组合并不仅仅用于 Kubernetes 集群监控,它还可以用于各种需要监控和可视化的场景。比如在你的业务场景中, 需要监控今/昨日的营收、昨日的 PV、今日的 UV、今日的订单量等。
3.4.4 采集容器指标(cAdvisor)
cAdvisor 是 Google 开源的一款用于展示和分析容器运行状态的可视化工具。通过在主机上运行 CAdvisor 用户可以轻松的获取到当前主机上容器的运行统计信息, 例如 CPU 使用率、内存使用量、网络带宽和磁盘使用量等。你可以参考 cadvisor 的安装与使用 来进一步了解它的基本原理和使用方法。
cAdvisor 暴露了 Prometheus 支持的指标格式,通过二者结合,我们可以轻松获取到 Kubernetes 集群中的 Pod 内部容器级别的监控数据。
[!NOTE] kubelet 也是通过内置 cAdvisor 来监控容器指标。
3.4.5 Metrics Server
Metrics Server 是 K8s 的一个附加组件,它实现了 API Server 定义的Metrics API。 Metrics API 主要为用户提供集群中处于运行状态的 Pod 和 Node 的 CPU 和内存使用情况, 设计用于 K8s 的 HPA(Horizontal Pod Autoscaling,Pod 水平自动伸缩)以及 VPA(Vertical Pod Autoscaling,Pod 垂直自动伸缩)功能。
Metrics Server 内部通过调用 kubelet API 来监控容器数据,然后通过 Metrics API 暴露给 API Server 使用。 当安装 Metrics Server 后,我们可以使用kubelet top命令来查看集群中 Pod 和 Node 的 CPU 和内存使用情况。关于它的安装和使用细节, 你可以参考笔者的另一篇文章K8s 进阶教程 中的 安装 Metrics Server 插件 一节。
了解更多:
3.4.6 自定义指标
前面我们说到使用 Prometheus+Grafana 的组合来监控 Kubernetes 集群,这种方式已经可以监控任何的指标数据。 如果我们想要把 Prometheus 中存储的指标数据通过暴露给 Kubernetes API Server,然后通过 kubectl 命令行来查询, 那我们可以通过自定义指标的方式来完成,这需要在集群中安装prometheus-adapter, 并在其配置文件中编写需要查询的指标信息,大致步骤请参考K8s 进阶教程 中的3.4.6 使用多项指标、自定义指标和外部指标。
但请注意,如果仅仅是为了方便使用 kubectl 来查询指标,那其实大可不必,因为性价比太低(有一定维护成本),使用 Grafana 查询足以。 使用自定义指标更多是为了完成 HPA(Horizontal Pod Autoscaling,Pod 水平自动伸缩)和 VPA(Vertical Pod Autoscaling,Pod 垂直自动伸缩)工作。
3.5 告警
有了指标数据后,我们需要根据 SLO(服务水平目标)来设置相应的告警规则(在 Grafana 中设置)。SLO 是对服务的某些可测量特性设置的目标期望, 例如可用性、吞吐量、频率和响应时间。如果没有 SLO,我们对服务就会抱有不切实际的期望,也无法设置合适的告警规则。 对于 Kubernetes 这样服务具有高度自愈能力的系统,我们应该针对终端用户的服务体验来设置告警规则。 例如,为前端服务设置的 SLO 是响应时间不得高于 20ms,当观测到一段时间内的平均响应时间高于 20ms,就需要及时发出告警。
下面是一些常见的注意点以供参考:
- 仅对关键指标进行告警,并忽略一些可以被 K8s 自动处理的指标,例如 CPU/内存利用率等
- 设置合理的阈值周期,避免过短的周期导致频繁告警。最后有一套阈值设置规范,来避免个性化的阈值设置。例如,可以遵循 5min、10min、30min、1h 这样的特定频率来统一配置阈值周期
- 在配置告警规则时,应该确保通知中包含必要的上下文信息,例如服务名称、告警持续时间、建议处理措施等
- 告警通知不要发给一群人,而是仅发给需要关注或处理问题的人,否则容易被当成不重要的信息而被忽略
4. 日志监控
日志监控是监控系统中的重要一环,它可以帮助我们快速定位问题和恢复服务。Kubernetes 中的日志监控目标包含:
- 节点日志(节点关键服务的日志。例如容器运行时组件的日志、内核日志等)
- Kubernetes 组件日志(如 API Server、ControllerManager 和 Scheduler)
- 容器日志(主要是应用日志)
- Kubernetes 审计日志(与权限相关,非常重要)
如果你使用云托管的 Kubernetes 集群,那建议你也使用托管的日志监控服务,这样有助于大幅降低运维成本。维护自建的日志服务起初看起来不错, 但随着环境复杂度的增长,维护工作会变得越来越费时费力。
如果选择自建日志服务,向你推荐笔者的另一篇文章Kubernetes 日志收集。 这篇文章会手把手指导你如何完成集群的日志收集工作。
5. CI/CD 流水线
CI/CD 的目标是构建一个完全自动化的过程,覆盖代码从提交到部署再到生产的全流程。我们应该避免进行手动更新,因为这样做很容易出错, 容易导致配置漂移,还会让部署变得脆弱,导致应用交付的整体敏捷性丧失。
构建一个高度集成的流水线能够让我们信心十足地将应用部署到生产环境,本节将具体介绍这个构建过程。
5.1 完整的流水线示例
如下:
- 推送代码变更到代码仓库(Git 或 SVN)
- 运行 APP 构建
- 运行 APP 测试
- 基于测试成功的 APP 代码构建镜像
- 推送镜像到镜像仓库
- 部署 APP 到 Kubernetes(可能基于不同的策略,如滚动更新、蓝绿部署和金丝雀部署)
5.2 代码版本控制
每个 CI/CD 流水线都始于版本控制,它用于维护应用代码和配置文件的变更记录。配置文件可能包括 K8s 清单以及 Helm Chart。 而版本控制策略则有多种选择,这取决于组织结构和责任划分。但请注意,应该尽量让开发者和运维工程师在同一个代码存储库中进行写作, 这有助于统一管理和保证代码和运维脚本物料始终保持匹配。
5.3 持续集成
持续集成(CI)步骤是将代码变更持续地集成到版本控制库的过程。具体来说, 就是将每一次代码提交都当做一个新的应用版本进行构建,这样一来就能及时发现哪一次代码提交导致构建失败,从而快速修复代码。
5.4 测试
当应用构建成功后,应该马上执行预设的测试命令。例如,Go 应用可以使用go test执行一组单元测试。 当测试通过时,才能将代码打包为镜像;一旦测试失败,应立即停止流水线工作,并提供此步骤失败的日志输出。
[!NOTE] 除了对应用的单元测试,你可能还需要预设其他测试脚本命令。例如,对 K8s 清单文件的风险检测命令以及对 Helm Chart 文件的 lint 测试命令。
5.5 镜像构建
在完成镜像构建时,我们需要提前写好 Dockerfile。这里我们需要注意以下几点:
- 使用多阶段构建减小镜像 Size
- 使用具有少量命令的基础镜像以减少安全风险,例如 Scratch、Alpine 和 Distroless 等
- 使用这类基础镜像时,你可能还需要了解它们的调试方法,以更好的在生产环境中使用
5.6 添加镜像标签
在将镜像推送到镜像仓库之前,需要给镜像打上标签。合理的镜像标签能够帮助我们快速识别镜像版本,在 CI 流水线中构建的每个镜像都应该拥有一个唯一的标签。
有以下几种标签策略可供使用:
- 构建号(在开始构建时由构件系统产生的一个递增编号)
- GitHash(代码提交时产生的 GitHash 码,有助于在代码提交记录中溯源)
- GitHash-构建号(推荐)
5.7 持续部署
持续部署(CD)步骤是将应用镜像部署到应用运行环境(如测试、预发布和生产环境)的过程。 这一步我们只需要在 CD 系统中提前配置好 Kubernetes 的 ServerUrl、证书以及 Token,然后由 CD 系统自动完成部署/更新步骤。
5.8 部署策略
本节讨论的部署策略,包括滚动更新、蓝绿部署和金丝雀部署。
5.8.1 滚动更新
滚动更新(rolling update)是 Kubernetes 中最常用也是 Deployment 默认的部署更新策略。它通过逐步更新 Pod 的方式,确保应用在更新过程中始终可用。
具体来说,在准备更新时,我们首先执行kubectl set image...命令来修改 Deployment 中应用容器的镜像标签。 然后,Kubernetes 会逐步更新 Deployment 中的 Pod,确保应用在更新过程中始终可用。在更新过程中, 如果由于镜像问题导致新的 Pod 无法正常启动,Kubernetes 会暂停更新,待我们解决问题后重新构建新的镜像,再重新操作此步骤完成更新。 此外,我们还可以下面的 kubectl 命令来辅助完成滚动更新:
- 通过
kubectl rollout pause命令来暂停滚动更新,并在确认新 Pod 正常启动且接受流量后再继续更新。 - 通过
kubectl rollout undo命令来回滚 Deployment 的本次更新,执行命令后 Deployment 内的应用容器的镜像标签将恢复到旧值, 同时当前更新失败的 Pod 也会被旧标签的镜像替换。
为了更好的实现热更新以及减少终端用户感知,建议在 Deployment 中配置readiness probe和preStop字段。 readiness probe用于确保部署的新版本 Pod 在准备就绪后才能接受流量;而preStop用于在 Pod 被删除前执行清理操作,例如应用进程的退出操作。
滚动更新时,集群中会同时存在新旧两个版本的 Pod,所以对于不支持多进程部署的应用(比如 Deployment 的replicas字段设置为 1), 注意要在 PodSpec 中设置更新策略为Recreate,而不是使用默认的rollingUpdate。
5.8.2 蓝绿部署
蓝绿部署是指在已经存在一套生产环境的应用的情况下,通过部署一套新的应用环境,然后将用户流量快速切换(通过负载均衡器)到新版本的应用上。 这个过程中,旧的环境叫做蓝(blue),新部署的环境叫做绿(green)。当新环境存在问题时,再快速切换到旧环境即可。 蓝绿部署最大的优点是实现零停机部署。
这套策略看似简单,实则存在不少难点。蓝绿部署通常意味着一次切换一整个环境。比如, 当前应用由一个副本数量为 10 的 Deployment 环境(如名为app-deploy-v1)组成, 那么还需要部署一套新的 Deployment 环境(如名为app-deploy-v2,但label不同),副本数量仍然为 10。这两套环境是同时存在的, 所以会占用增加一倍的硬件资源。然后我们需要对新的 Deployment 进行完整的测试,测试通过后, 在 Kubernetes 的 Service 模板中修改 Selector 来切换流量到新的 Deployment。待新环境正常运行一段时间后(由具体情况决定),再销毁旧的环境。
这里,简要列出蓝绿部署的几个难点:
- 多版本同时存在的问题。应用必须支持多版本同时存在,否则不适用本部署方法。
- 数据库迁移问题。应用通常会访问数据库,而且需要执行事务。操作者必须考虑到新旧版本对同时执行事务操作的兼容性,确保数据一致性和完整性。
- 需要具备同时维护两套环境的能力。
- 由于更新粒度大,虽然可以快速切换流量,但可能会因为操作失误导致严重的服务中断影响。一定要进行预先的、多次的完整流程操作演练。
5.8.3 金丝雀部署
金丝雀部署是比蓝绿部署更保守一点的部署策略。首先,金丝雀部署策略中,也需要同时部署两个基本相同的环境。最大的不同是, 金丝雀部署中,用户流量是按比例或条件逐渐切换到新环境,而不是像蓝绿部署那样一次性地全部切换。 例如,你可以将携带特定 Header 键值的请求路由到新环境。
[!NOTE] 在大部分移动应用项目中,客户端人员通常会通过特定的 Header 键值来标识当前用户使用的包环境,比如测试包/正式包/灰度包。
金丝雀部署相对蓝绿部署的优点是,可以小范围验证新版本的应用,确保新版本的应用在生产环境中没有问题后再完全切换。 即使新环境存在问题,其影响也限制在较小范围。这种发布方式通常也叫做 A/B 发布或灰度发布。
在 Kubernetes 中可以通过 Ingress 来实现按比例分配流量的功能,常用的 Ingress 控制器如 Nginx、Traefik 等都支持。 分配流量的策略包括 HTTP Header 的 Key/Value、Cookie、比例配置等。
注意,实践金丝雀部署时需要处理与蓝绿部署相同的问题,包括多版本共存、数据库迁移等。
5.8.4 使用 Helm
Helm 是一个流行的 Kubernetes 应用的包管理工具,我们可以在前面提到的部署策略中用到它。
Helm 使用一种叫做 Chart 的包结构来组织编排 Kubernetes 应用, 一个 Kubernetes 应用可包含多个 Kubernetes 资源(包括 Deployment、ConfigMap/Secret、Job 等在内的各类资源)。 使用 Helm,我们的 Kubernetes 应用就直接拥有了版本管理机制,并且可以通过 Helm 命令进行快速的升级和回滚。 此外,Helm 最关键的特性是支持通过 Go Template 支持模板化配置,这个特性让我们无需频繁修改 Chart, 而是通过 CD 命令来将参数注入 Chart。
比如,我们由一个 Web 后端应用,在使用 Helm 之前,这个应用由两个 Deployment 组成(比如 User 和 DB 两个服务)。 然后假设这两个服务都需要在本次迭代中进行升级,若不使用 Helm,则需要一个一个升级(执行两次升级操作); 若使用 Helm,这两个 Deployment 就同时存在于一个 Chart 中,我们直接编辑好新版本的 Chart,然后在 CD 命令中执行 Helm 升级命令即可。 即使有问题,也可以一次性回滚 Chart 内的所有资源,而不是一个个回滚。可见,Helm 大大提高了部署和回滚的效率。
如果你想要进一步了解 Helm,可以参考我的另一篇文章Helm 手记。
5.9 一些建议
CI/CD 流水线配置很难一开始就做到完美,但可以参考下面原则来尽可能完善流程:
- 在 CI 中关注自动化和构建速度。优化构建速度能够在代码提交时快速完成构建,为开发者提供更快速的反馈。
- 在流水线中配置可靠且完善的测试脚本。以便在代码提交时,能够快速找到代码中的问题,以便快速修复和验证。
- 尽可能优化镜像大小,这样可以减少拉取镜像的时间,提高构建速度,还能减少容器运行时的内存消耗和受攻击面。
- 如果还不熟悉 CD,可以先从简单易用的滚动更新开始。后续再考虑使用金丝雀发布或蓝绿部署。
- 在 CD 环节,一定要注意对客户端连接的重新建立和数据库结构的变更进行充分测试,尽可能减少对用户端的影响。
- 生产环境中进行测试时,应该从小规模开始,逐步扩大测试范围。
6. 资源管理
当应用部署到 Kubernetes 集群中以后,我们的工作还没有结束,因为实战中总是会出现各种各样的突发状况, 比如,某个服务突然变得非常慢,某个服务突然变得不可用,某个服务需要增加实例数量,某个服务需要减少实例数量等等。 为了应对这些突发状况,我们需要使用 Kubernetes 内置的一些资源管理功能。
具体来说,本节将会介绍以下 Kubernetes 功能:
- Pod 调度原理
- Pod 调度技术
- Pod 的亲和与反亲和
- 节点的亲和与反亲和
- 节点选择器
- 污点和容忍度
- 指定节点名称
- Pod 资源管理
- Pod 资源请求和限制
- Pod 服务质量
- PodDisruptionBudget
- Namespace 维度的资源管理
- ResourceQuota
- LimitRange
- 资源伸缩
- Pod 水平伸缩
- Pod 垂直伸缩
- 节点水平伸缩
本文会对这些功能进行一个大致的介绍以及给出相应的参考🔗,但介于篇幅不会对每个功能都进行详细的使用介绍。
6.1 Pod 调度原理
当一个 Pod 被提交到 Kubernetes 集群中以后,kube-schduler会负责决定 Pod 最终运行在哪个节点。 具体来说,kube-schduler的调度算法大致分为预选、优选和绑定三个阶段。
预选阶段主要是通过一些内置规则来过滤掉不符合需求的节点。比如,节点资源是否满足 Pod 的资源请求和限制, 节点是否满足 Pod 的亲和与反亲和规则等等。具体的内置规则介绍可以查看Kubernetes 进阶教程-预选阶段。
优选阶段则是在预选阶段选出的节点列表中进一步对这些节点进行打分,当然也是根据一些内置规则。比如节点空闲资源多的得分更高、未运行相同应用 Pod 的节点得分更高等等。 具体的内置规则介绍可以查看Kubernetes 进阶教程-优选阶段。
绑定阶段是选择分值最高的节点作为 Pod 运行的目标节点进行绑定(如有多个,则随机一个)。
6.2 Pod 调度技术—Pod 的亲和与反亲和
Pod 的亲和与反亲和是一项可供手动配置的 Pod 资源调度技术,它属于前面提到的优选阶段的一种规则。 我们可以通过设置它来决定如何部署相关联的一组 Pod。
例如,为 Pod 设置亲和性规则可以让 Pod 仅运行或尽可能运行在满足条件(这些节点运行了某些偏好 Pod)的节点上,理由可能是为了集中管理某些 Pod。 同理,Pod 的反亲和性规则是让 Pod 必须或尽可能不运行在满足条件的节点上,理由可能是远离运行了某些 Pod 的节点。
如果你想进一步了解此项技术的使用配置方法,可以参考Kubernetes 进阶教程-Pod 亲和性和反亲和性。
6.3 Pod 调度技术—Node 的亲和与反亲和
Node 的亲和与反亲和与 Pod 的亲和与反亲和类似,只是它的配置目标针对的是节点而不是 Pod, 请直接参考Kubernetes 进阶教程-节点亲和性。
6.4 Pod 调度技术—节点选择器
nodeSelector 是将 Pod 调度到特定节点最简单的方法。使用步骤是先为目标节点设置标签,然后在 PodSpec 中设置 nodeSelector 字段。 需要注意的是,nodeSelector 是一项硬性调度配置,若没有满足标签要求的节点,则 Pod 将无法调度到任何节点上(处于 Pending 状态)。 例如,你可能希望将 Pod 调度到具有特定硬件配置(如 GPU)的节点上。
6.5 Pod 调度技术—污点与容忍度
污点与节点绑定,节点拥有污点后防止 Pod 被调度到该节点,除非 PodSpec 中配置了容忍度(针对该污点)。 每个节点都可以设置污点(taint),污点是一个键值对(值可忽略)和污点效果的形式,比如role/log:NoSchedule。
污点与反亲和性类似都是用来排斥 Pod,但它们之间有一个重要区别,那就是污点默认排斥所有的 Pod(直到为 Pod 设置了对应污点的容忍度)。 例如,在上线某些 GPU 节点时,就可以将它们设置污点,这样 Pod 就不会被调度到这些节点上,直到你手动为那些需要 GPU 的 Pod 设置容忍度。 还有就是可以用来排空节点,比如现在想要下线或维护某个节点,就可以为其设置一个污点叫做maintaining:NoExecute, 在短暂时间后,Kubernetes 就会排空该节点上的 Pod(强制排空),当 Pod 被排空后,就可以将节点下线或进行维护。
6.6 Pod 调度技术—指定节点名称
通过在 PodSpec 中指定nodeName字段,可以让 Pod 直接调度到指定节点上,并且可以自动容忍节点上的除了包含NoExecute影响以外的污点。 这个特性由于灵活性较低所以使用较少。使用时需注意,若节点名称不存在于集群的节点列表中,则 Pod 将无法调度到任何节点上,通过kubectl get po 也无法看到 Pod。
6.7 Pod 资源管理—请求和限制
在实践中,一般都需要在 PodSpec 中设置容器的requests和limits字段,分别表示 Pod 内容器对 CPU 和内存的最低需求和最高限制, 前者可以保证 Pod 能够正常调度到资源足够的节点上运行,后者是为了避免 Pod 占用过多节点资源影响到节点上的其他应用。当 Pod 对资源的占用达到限制后, Pod 可能因为 OOM 而重启或调度到其他节点。
当你安装了 MetricsServer 后,就可以通过kubectl top nodes命令查看所有节点的资源使用情况,如下所示。
# CPU资源是以millicore(m)为单位,1000m=1core
# 内存资源是以byte为单位,1Mi=1024Ki=1024*1024bytes
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
test-1.27-control-plane 241m 6% 559Mi 14%
test-1.27-worker 105m 2% 742Mi 18%
test-1.27-worker2 93m 2% 1788Mi 45%根据这些信息我们可以知道所有节点的 CPU 和内存的已使用情况,从而知道何时该为集群增加节点。同时也可以使用kubectl top po 查看 Pod 对节点资源的使用情况。
6.8 Pod 资源管理—服务质量(QoS)
Pod 被创建后会被分配一个 QoS 等级,当节点资源不足时,会根据 Pod 的 QoS 等级作为依据来驱逐某些 Pod。 具体分配的 QoS 等级由 Pod 的资源请求和限制决定。一共有以下 3 种 QoS 等级:
- Guaranteed:当 Pod 中每个容器(包含初始化容器和普通容器)都定义了 CPU 或内存的
requests和limits且数额相等时,分配此等级。- 最高优先级,当节点资源不足时,系统会选择 Kill 其他两种优先级的 Pod 来保证此等级 Pod 的正常运行。
- Burstable:当 Pod 中存在一个容器的 CPU 或内存的
requests小于limits时,分配此等级。- 次高优先级,当节点资源不足时,系统会选择 Kill BestEffort 等级的 Pod 来保证此等级 Pod 的正常运行。
- BestEffort:当 Pod 中没有任何容器设置对 CPU 或内存的
requests和limits时,分配此等级。- 最低优先级,当节点资源不足时,系统会优先 Kill 此等级的 Pod。
注意,若某个容器只设置了 CPU 或内存的limits字段但未设置requests,Kubernetes 会自动为其设置与限制相等数额的请求。
查看 Pod 服务质量等级的命令:
kubectl get po xxx -o jsonpath='{ .status.qosClass}{"\n"}'所以,为了避免 Pod 被 Kill,应该尽可能为重要业务的 Pod 设置 Guaranteed 的 QoS 等级。
6.9 Pod 资源管理—PodDisruptionBudget
正常运行的 Pod 可能在某个时候被人工或控制器驱逐(相当于删除),驱逐原因分为两类:主动 驱逐和被动驱逐。主动驱逐是指用户或控制器明确地执行了删除操作(包括对 Pod 模板的更新、排空节点等); 而被动驱逐是指由于节点资源不足,Kubernetes 系统根据 QoS 等级选择性地驱逐 Pod,被动驱逐还包括硬件故障、网络分区或内核崩溃等异常情况。
任何原因导致的驱逐都可以成为干扰(Disruption),为了最大程度减少干扰对应用的影响, Kubernetes 允许我们设置 PDB 来保证发生干扰时应用仍然能够正常运行。具体来说,PDB 可以设置在发生干扰时, 与指定标签匹配的 Pod 最多可以被关闭的数量或百分比、最少可用的 Pod 数量或百分比。
当进行排空(drain)操作时,如果违反 PDB 策略,排空命令将进入阻塞。
[!IMPORTANT] 工作负载资源(Deployment、StatefulSet 或 ReplicaSet 等)在滚动升级时不会触发 PDB。
PDB 的示例模板:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
# minAvailable 和 maxUnavailable 只能设置其一,两者都支持整数和百分比
minAvailable: 2
# maxUnavailable: 10%
selector:
matchLabels:
app: zookeeperPDB 根据 selector 匹配一组 Pod,它们可以是某个控制器(如 Deployment 或 StatefulSet 等)下的 Pod,也可以是独立的 Pod。
6.10 Pod 资源管理—ResourceQuota
当多个团队或多个不同类别的应用共享一个集群时,我们可能需要将它们安置在不同的命名空间下进行管理。进一步, 我们还需要对每个命名空间的资源额度进行限制,否则就会互相影响,导致意外结果。
ResourceQuota 是用于管理单个命名空间的总资源限额的 Kubernetes API 对象。它可以为以下资源进行限额:
- CPU/内存的请求和限制
- 存储卷总量
- PVC 个数
- Pod/Service/Deployment/ReplicaSet 等资源的个数
当命名空间中的资源使用量达到限额就会触发错误提示。
6.11 Pod 资源管理—LimitRange
ResourceQuota 是管理单个命名空间的总资源限额,但我们还需要对命名空间下的单个对象所使用的资源进行限额,否则在命名空间内的对象也会互相影响。 而 LimitRange 则可以帮助我们达成目标,例如,它可以设置命名空间下 Pod 的默认 CPU/内存的请求和限制的数值,当 Pod 的设置超出限制时无法部署, 同时当 LimitRange 配置后,新的(包括控制下的)Pod 必须设置 CPU/内存的请求和限制,否则也无法部署。
除了 Pod,LimitRange 还可以针对容器、PVC 等许多对象进行配置。
6.12 资源伸缩—Pod 水平伸缩
当 Kubernetes 中的应用突然面临业务高峰期,固定副本数量部署的 Pod 无法满足业务需求时, 我们可以通过 Horizontal Pod Autoscaler(HPA)对 Pod 进行水平伸缩。 HPA 是 Kubernetes 提供的对象,可以帮助我们根据 Pod 的 CPU/内存使用率自动调整 Pod 的副本数量,从而实现 Pod 副本数量的自动伸缩。
除了使用 Pod 的 CPU/内存使用率作为伸缩指标,还支持使用自定义指标,但这需要额外部署资源来作为指标来源。
6.12 资源伸缩—Pod 垂直伸缩
HPA 是一种简单直接的增加服务端吞吐量的方式,但如果 Pod 由多个容器组成,而只有一个接收流量的应用容器,HPA 可能会造成一些资源浪费。 此时,使用 Vertical Pod Autoscaler(VPA)可以实现 Pod 的垂直伸缩。 VPA 是 Kubernetes 提供的对象,可以帮助我们根据 Pod 中所有容器的 CPU/内存使用率自动调整 Pod 中所有容器的 CPU/内存的请求和限制的数值, 从而实现 Pod 中所有容器的 CPU/内存的自动伸缩。
VPA 并不是 Kubernetes 原生提供的功能,而是由社区提供的,需要以自定义资源的方式进行安装。VPA 提供四种工作模式:
- auto:VPA 在 Pod 创建时为其分配资源请求,并在 Pod 运行时根据 Pod 的资源使用率自动调整资源请求。
- 当前的更新是通过删除重建(等效于
recreate)的方式,一旦 Kubernetes 支持原地更新,VPA 将切换到原地更新模式。
- 当前的更新是通过删除重建(等效于
- recreate:VPA 在 Pod 创建时为其分配资源请求,并在 Pod 运行时根据 Pod 的 CPU/内存使用率自动调整资源请求,更新是以删除重建的方式进行。
- initial:VPA 只在创建 Pod 时分配资源请求,以后不会更改。
- off:VPA 不会自动更改 Pod 的资源请求。
下面是一个 VPA 配置实例(安装 VPA 后可用):
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"VPA 的使用比较复杂,有许多需要注意的点。例如,VPA 不建议与 HPA 同时使用(除非 HPA 使用自定义指标作为参考)。若要使用 VPA,请阅读 VPA 文档, 并进行详尽的测试后再投入生产。
6.13 资源伸缩—节点水平伸缩
当面对具有更大突发流量的业务时,考虑实施节点维度的自动水平伸缩是一个不错的选择。 但目前的集群自动伸缩功能仅支持在公有云上运行,这点需要注意。
节点的水平伸缩会在以下两种情况自动触发:
- Pod 由于资源不足而无法启动时(增加节点)。
- 集群中存在已经在较长的时间段内未被充分利用的节点,并且它们的 Pod 可以被放置在其它现有节点上(缩减节点)。
节点水平伸缩是一个高级的主题,考虑在合适的时机去增减节点(以及增减哪些节点)是一个十分复杂的决策过程, 这其中需要考虑到 Pod 亲和性和反亲和性、污点、运行 PDB 的 Pod 的节点等等。若你直接使用云托管的 K8s 集群, 则可以直接使用云厂商原生支持的集群节点自动伸缩功能,而无需自行运维此功能。
7. 网络策略与 Pod 安全
7.1 网络策略
默认情况下,集群中的工作负载(Deployment 等控制器下的 Pod)资源的网络通信是开放的,可以随意访问。 这包括(可能跨命名空间的)Pod 之间和 Pod 与外部世界之间的互通性。 开放访问虽然减少了运维复杂度和困扰,但同时也带来了风险。例如,DB 服务应该只允许被部分运行后端服务的 Pod 访问, 那些前端应用 Pod 和外部世界绝不应该访问到 DB 服务。此时,应该有一条 ACL(访问控制列表,传统网络层面的术语)来实现此目标。
好在,Kubernetes 提供了一个叫做NetworkPolicy的 API 资源来为集群的网络层(第四层)保驾护航。 NetworkPolicy 可以被看做是集群中的一个东西向流量防火墙,每个策略规则都通过podSelector属性来匹配一组 Pod,同时控制它们的流量出入。 每条网络策略都应用于 Pod 流量的一个或两个方向,即Egress(出站方向)和Ingress(入站方向), 每个方向指定目的地或来源时都可以选择三种方式限定:匹配某些标签的一组 Pod、一个 IP 块或匹配某些标签的命名空间,它们之间可以同时指定,是或的关系。 同时还可以指定哪些端口和协议(支持 TCP/UDP)可以被访问,或作为目的地。
注意几点:
- 每个方向都可以指定多个目的地或来源,这些目的地或来源之间是或的关系。但进一步,每个目的地或来源又可以由上面提到的三种方式进行任意组合,组合后的结果是且的关系,具体请参阅官文。
- 简单的总结就是外或内且。
- 对于除了 TCP/UDP 以外的协议的过滤支持,取决于集群所安装的 CNI 网络插件。
- 对于使用
hostNetwork的 Pod,NetworkPolicy 无法保证对其生效。- 这类 Pod 对外访问时具有与节点相同的 IP,可以使用
ipBlock规则允许来自hostNetworkPod 的流量。
- 这类 Pod 对外访问时具有与节点相同的 IP,可以使用
- 不管是出站还是入站流量策略,都是叠加生效的,最终效果不受顺序影响。
- 由此推断,较多的网络策略会影响集群网络性能。
- 新增策略对现有连接的影响是不确定的,具体行为由 CNI 网络插件决定。
- 例如,旧策略是允许来自某个源的访问,应用的新策略则是拒绝这个源的访问,此时是立即切断现有连接还是仅对新连接生效 取决于 CNI 网络插件的实现。
- 支持 NetworkPolicy 的 CNI 网络插件有:Calico、Antrea、Cilium、Kube-router、Romana、Weave Net 等。注意,Flannel 不支持。
7.1.1 出站流量
当没有Egress策略时,它将默认允许 Pod 的所有出站流量。当存在一条Egress策略时:
- 它将控制(且仅)一组通过
podSelector匹配的 Pod 的出站流量; - 它将允许匹配的一组 Pod访问指定目标的流量,同时默认允许这个目标网络的应答流量(不需要 Ingress 规则允许);
- 若策略没有指定出站目标,则表示不允许任何出站流量;
- 所匹配的这组 Pod 访问任何非本地、且非目标的流量都将被拒绝,除非有其他 Egress 策略放行。
- 若策略没有指定
podSelector(该字段留空),则表示策略所在命名空间下的所有 Pod 都将应用此策略,通常用于默认拒绝出站规则。
7.1.2 入站流量
当没有Ingress规则时,它将默认允许 Pod 的所有入站流量。当存在一条Ingress策略时:
- 它将控制(且仅)一组通过
podSelector匹配的 Pod 的入站流量; - 它将允许一组匹配的 Pod接收指定的来源网络的流量,同时默认允许流向这个来源网络的应答流量(不需要 Egress 规则允许);
- 若策略没有指定入站来源,则表示不允许任何入站流量;
- 所匹配的这组 Pod 不会收到任何非本地、且非指定来源的流量(被网络插件拒绝),除非有其他 Ingress 策略放行。
- 若策略没有指定
podSelector,则表示策略所在命名空间下的所有 Pod 都将应用此策略,通常用于默认拒绝入站规则。
注意,要允许从源 Pod 到目的 Pod 的某个连接,源 Pod 的出口策略和目的 Pod 的入口策略都需要允许此连接, 除非流量源没有应用任何出站策略或流量目的地没有应用任何入站策略。
7.1.3 示例
示例模板:network-policy.yaml
模板将实现以下目标:
- 默认拒绝 default 命名空间下的所有 Pod 的入站流量;
- 允许 default 命名空间下携带标签
access-db: mysql的 Pod 访问 MySQL 服务(携带标签db: mysql),策略应用于 DB 侧的入站流量; - 拒绝 default 命名空间下携带标签
internal: true的 Pod 的出站流量; - 允许 default 命名空间下携带标签
internal: true的 Pod 访问20.2.0.0/16网段且目标端口是 5978 的 TCP 端口。
[!NOTE] 该示例没有完全展示出
Ingress和Egress的规则组合,更完整的示例请参考官方的 NetworkPolicy 文档。
7.2 Pod 安全
7.2.1 Pod 安全策略
虽然 K8s 拥有 RBAC 的权限控制机制,但 RBAC 仅能限制用户对 K8s API 对象(如 Pod/Deployment/Service 等)的访问, 无法限制 Pod 内部的安全权限(例如拥有特权/访问宿主机文件系统/特权提升/使用 hostNetwork/设置 seLinux 等)的使用。 一个不安全的镜像,或者一个配置了特权权限的容器,都可能导致集群的安全问题。
因此,早在 v1.3 版本中,K8s 就提供了 PodSecurityPolicy(PSP) 这项 API 对象来为 Pod 设置安全策略。 PSP 可以防止 Pod 未经授权的获取节点 root 权限或访问节点的其他敏感资源(如网络/文件系统等),从而影响集群的安全。
PodSecurityPolicy 的废弃
- 由于 PSP 在使用上的繁琐以及部分限制,在 v1.21 版本中,PSP 被标记为
Deprecated,并在 v1.25 版本中正式去除。 - 弃用 PodSecurityPolicy:过去、现在、未来
所以,本文不会介绍 PSP 的使用,感兴趣的读者可以查阅官方文档。
7.2.2 Pod 安全准入控制器
弃用 PSP 后,K8s 官方重新构思并实现了一套新的 Pod 安全控制机制叫做 Pod 安全准入控制器(Pod Security Admission Controller), 这套机制致力于在保留 PSP 大部分功能的同时提升了使用上的简便性,最大的特点是支持柔性上线能力。
Pod 安全准入控制器是 K8s v1.22 版本引入的一项功能(此版本需要修改 API-Server 的启动参数进行手动开启),在 v1.23 版本中作为 Beta 特性默认开启。 不过,这项功能并不像 PSP 那样通过 API 对象来提供能力,而是通过 K8s 原有的准入控制器(Admission Controller)来提供能力。 具体来说,新的功能首先提出了一个 Pod 安全性标准为 Pod 定义了不同的隔离级别,这些标准能够让你以一种清晰、一致的方式定义 Pod 的安全行为。其次,新功能增加了一个叫做 PodSecurity 的准入控制器,它将在命名空间维度来执行这个 Pod 安全标准。
Pod 安全标准定义了三个隔离级别:privileged、baseline 和 restricted,从左到右分别是特权/基准/严格,限制程度从低到高。 我们需要先为命名空间设置一个安全标准,以及一个模式表示违反标准时该如何处理,可以设置多个标签,且安全标准和模式可以任意组合。 一共有三个模式可用:enforce/audit/warn,其中 enforce 是强制模式(拒绝违反安全标准的 Pod),audit 是审计模式,warn 是警告模式。
下面的清单定义了一个my-baseline-namespace命名空间,声明了如下限制:
- 阻止任何不满足 baseline 策略要求的 Pod;
- 针对任何无法满足 restricted 策略要求的、已创建的 Pod 为用户生成警告信息, 并添加审计注解;
- 将 baseline 和 restricted 策略的版本锁定到 v1.29。
# 本模板来自官网示例
apiVersion: v1
kind: Namespace
metadata:
name: my-baseline-namespace
labels:
# 形式:pod-security.kubernetes.io/<MODE>: <LEVEL>
pod-security.kubernetes.io/enforce: baseline
# 形式:pod-security.kubernetes.io/<MODE>-version: <VERSION>
# 注:这个标签表示此模式按照指定版本的规则进行检查,如果未指定,则按当前K8s版本
# - 例如,v1.24 及之前版本的 Kubelet 不强制检查 PodSpec中的 OS 字段,若你也不希望检查此字段,则需要锁定到v1.24 及之前的版本
# - (但如果当前版本比锁定版本还低,则使用当前版本,即使用二者之间较低的版本对应的检查规则)
pod-security.kubernetes.io/enforce-version: v1.29
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/audit-version: v1.29
pod-security.kubernetes.io/warn: restricted
pod-security.kubernetes.io/warn-version: v1.29在应用这个清单后,准入控制器会检查当前命名空间中存在的 Pod,任何违反 enforce 策略要求的 Pod 都会通过警告的形式提示。对于已存在的命名空间,可以通过 kubectl label 命令进行修改。
为命名空间设置好安全标准标签后,接下来就是按照所设置的安全标准来填写/纠正 Pod 模板。不同的安全标准级别对 PodSpec 中字段的要求不同, privileged是特权级别没有限制;而baseline和 restricted则存在诸多限制。 具体要求在 Pod 安全性标准—Profile 页面中可以找到。
例如,按照上面的清单创建的my-baseline-namespace命名空间,在创建 Pod 时,需要按照baseline安全标准来填写 PodSpec。 部署下面的 Pod 清单将会被拒绝,并得到提示:Error from server (Forbidden): error when creating "pod_curl.yaml": pods "curl" is forbidden: violates PodSecurity "baseline:v1.29": host namespaces (hostNetwork=true)。
# pod_curl.yaml
apiVersion: v1
kind: Pod
metadata:
name: curl
namespace: my-baseline-namespace
spec:
hostNetwork: true
containers:
- name: curl-container
image: appropriate/curl
command: [ "sh","-c", "sleep 1h" ]需要注意的是,enforce模式仅对原生 Pod 生效,不会对 Pod 控制器(如 Deployment)生效。其他两种模式则是对控制器和原生 Pod 都生效。
7.2.3 白名单
Pod 安全准入控制器会对命名空间下的所有 Pod 或控制器的 PodSpec 进行安全规则校验, 如果 PodSpec 中存在不安全的字段设置,则拒绝创建 Pod 或给出提示。但凡事总有例外,Kubernetes 就允许在准入控制器中静态配置这些例外, 这里我们称作白名单,官方称作豁免(Exemptions)。
白名单可以通过三种方式配置:
- Username:免去对指定用户创建的原生 Pod 的安全检查,控制器除外。
- RuntimeClassName:免去对包含指定运行时类的 Pod 或控制器的安全检查。
- Namespace:免去对指定命名空间下所有 Pod 或控制器的安全检查。
具体配置方式并不复杂,请参阅官网文档。
8. 服务网格
本节是一个笔者新增的一个大章节,严格来说本节主题与 K8s 并不绑定,但笔者认为服务网格是在 K8s 中运行微服务架构的一个流行的发展方向(其实在大厂或国内早已普遍应用)。 可能由于早期的文档或教程缺失,导致国内开发者对服务网格的认知和实践步骤并不清晰,因此在本节中,笔者将结合 一些权威书籍、官方指导以及笔者在实际生产环境中的实践经验,对服务网格进行一个系统的理论和实践介绍。 此外,本章节也将作为一个特别篇在项目主页中进行展示。
此章节中的演示将继续复用第一节中的 demo 项目。
8.1 出现时间与背景
早在十多年前,国外就开始流行起了从单体服务转向微服务架构的潮流,并在 2014 年传入国内。 微服务架构的优点也是有目共睹的,例如松耦合、快速迭代、高可扩展性、支持语言异构等。也正是微服务架构带火了云原生概念, 因为微服务的诸多优点都能够在云原生环境下得到完美体现。
然而,想要在企业中部署微服务架构也不是那么容易。由于微服务架构的多服务以及单服务多副本等特性, 保证服务间的正常、高效且安全的通信是一个需要密切关注的问题。传统微服务架构中, 我们需要为每个服务配置服务发现、负载均衡、服务路由、服务监控、服务容错等基础设施。当然, 我们可以为相同语言实现的微服务配置相同的一系列基础设施,但一旦出现其他语言构建的服务, 则又要单独去添加这些基础设施,这就造成了重复工作,还带来了大量的排错及维护成本。
上面提到的一系列基础设施,它们可能是由不同的第三方包提供(也叫做基于 SDK 的架构模式), 这种独立分散的方式也带来了服务组件的版本管理、依赖管理、服务部署、服务监控等问题的困扰。 并且使用它们的逻辑一定程度上耦合在业务代码中,这也使得整个代码库变得臃肿且增加了复杂度。
服务网格的诞生
为了解决上述问题,服务网格应运而生。服务网格是一个基础设施层,它位于应用程序和基础架构之间, 为应用程序提供服务间通信功能。服务网格由一系列轻量级网络代理组成,这些代理部署于每个应用实例旁(以 sidecar 模式), 并负责处理服务间的通信,包括服务发现、负载均衡、服务路由、服务监控、服务容错等。从此, 业务代码库中不再需要包含涉及处理服务间网络通信的逻辑,团队成员的编程工作又回归到单体服务架构的开发模式中, 即只需要专注于业务逻辑的开发。
世界上首个 Service Mesh 产品是国外的 Buoyant 公司在 2017 年 4 月发布的 Linkerd。 同时,Service Mesh 概念也是由这家公司的 CEO William Morgan 提出,他同年发表的文章 What’s a service mesh?And why do I need one? 是对 Service Mesh 概念公认最权威的定义。
之所以称为服务网格,是因为有了代理之后,所有服务间的通信都变成代理间的通信,而这些代理间的通信又形成一个巨大的网格, 并且整张网格都由一个统一的控制平面来进行管理。这可以通过下面的图加深理解
8.2 定义
"Service Mesh 是一个处理服务通讯的专门的基础设施层。它的职责是在由云原生应用组成服务的复杂拓扑结构下进行可靠的请求传送。 在实践中,它是一组和应用服务部署在一起的轻量级的网络代理,对应用服务透明。" —— William Morgan
具体来说,Service Mesh 使用的网络代理本质上是一个容器,它以 sidecar 模式部署在每个微服务侧(对应用实例完全透明), 并且它会接管同侧的应用实例发出和接收的流量,根据配置规则, 它可以对流量进行重定向、路由、负载均衡、监控、熔断等原来需要由多个工具完成的操作。 Service Mesh 将服务通信及相关管控功能从业务程序中分离并下层到基础设施层,使其和业务系统完全解耦。
8.3 控制平面
最初的 Service Mesh 产品形态中,并不存在统一的控制平面,每个代理的配置规则的变更都需要单独手动操作,这就显得十分麻烦。 但很快(也是 2017 年),以 Istio 为代表的第二代 Service Mesh 产品形态出现了,它们都具备一个统一控制平面,代理则称为数据平面。 通过控制平面,我们可以集中管理所有代理的配置规则(还包括代理的数据采集等功能), 而数据平面的每个代理还负责采集和上报网格流量的观测数据。
8.4 Istio
虽然到目前为止,在 CNCF 旗下托管的 Service Mesh 生态圈已经呈现繁荣姿态,例如 Linkerd、Istio、Consul Connect、Kuma、Gloo Mesh 等。 但由于庞大的贡献者数量和社区支持,最终Istio 成为服务网格领域的领先者。能够与之比较的是商业产品 Linkerd,它的优势是更轻量, 适合部署在中小规模云环境中,但缺少部分 Istio 才有的高级功能。关于 Istio 与 Linkerd 的详细对比,请查看 Istio vs Linkerd: The Best Service Mesh for 2023。
Istio 最初由 Google、IBM 和 Lyft 等公司共同开发。在 2018 年发布了其 1.0 版本。随后,Istio 在 2022 年 4 月宣布捐赠给 CNCF(正式孵化时间是同年 9 月底), 最终 Istio 在 2023 年 7 月正式毕业(不到一年),且如今已经有 数百家 公司为其贡献代码。 截至当前(2024 年 3 月 5 日),它已迭代至 v1.20,可见其发展之迅速。
Istio 的口号
“Simplify observability, traffic management, security, and policy with the leading service mesh.”
使用领先的服务网格技术来简化可观测性(WebUI、4/7 层流量指标、延迟、链路跟踪、健康检查、日志、网络拓扑)、 流量管理(负载均衡、多集群流量路由、服务发现、熔断/重试/超时/限速、动态配置、HTTP 1.1/2/3 支持、TCP/gRPC 支持、延迟注入等)、 安全(认证、mTLS 等)和策略。
[!NOTE] Istio 目前在中国互联网公司中并没有大量普及,这主要是由于其上手成本较高,在生产环境中应用 Istio 需要团队中至少有一位 Istio 专家或有丰富实践经验之人,而且最好对 Istio 的原理有深入的理解,这样 才能在出现问题时不会手忙脚乱。
此外,根据个人经验,如果你环境中的微服务数量低于 10 个,不建议使用 Istio,因为它的上手和维护成本可能会超过其带来的收益。
8.4.1 基本架构
部署后的 Istio 架构包含两个部分:
- 数据平面:又叫数据层,由 N 个代理服务(每个代理都是一个叫
istio-proxy的 sidecar 容器,它基于 Envoy)组成, 负责网格中的服务通信和流量管控,同时会收集和上报网格流量相关的观测数据。- 早期通过人工的方式将 Envoy 容器硬编码到每个工作负载模板中,后期发展至可以通过 Istio 的 sidecar 注入功能在部署工作负载时自动向模板注入 Istio 容器(通过 K8s 提供的 Webhook 机制), 大大提高使用效率,避免了对业务负载模板的入侵。
- 代理服务会劫持应用容器发出和接收的流量,然后按配置进行相应的处理,最后再决定是丢弃还是将流量转发出去。
- 向应用 Pod 注入 sidecar 容器时,同时还会注入一个
istio-init初始化容器,负责设置 Pod 的 iptables 规则,以便入站/出站流量通过 sidecar 代理转发。 - Istio 会跟踪 K8s 集群中的 Services 和 Endpoints 的变化,进而下发到每个 Envoy 代理中,让其可以知晓转发的实际目的地址。
- 控制平面:又叫控制层,由一个叫做
istiod的服务组成,负责整个数据平面的配置规则(运行时)下发和观测数据的管理。同时支持身份标识和证书管理。- istiod 内部有三大组件:Pilot、Citadel、Galley
- Pilot 负责收集和分发网格中的服务配置信息,包括服务发现、负载均衡、路由规则、访问控制等。
- Citadel 负责为网格中的服务提供身份标识和证书管理,包括服务证书的签发、过期提醒、密钥轮换等。
- Galley 负责对用户提供的配置进行格式以及内容验证、转换和下发,它直接与控制面内的其他组件通信,主要负责将控制面的其他组件与底层平台(如 K8s)解耦。
- istiod 内部有三大组件:Pilot、Citadel、Galley
Istio 架构图如下:
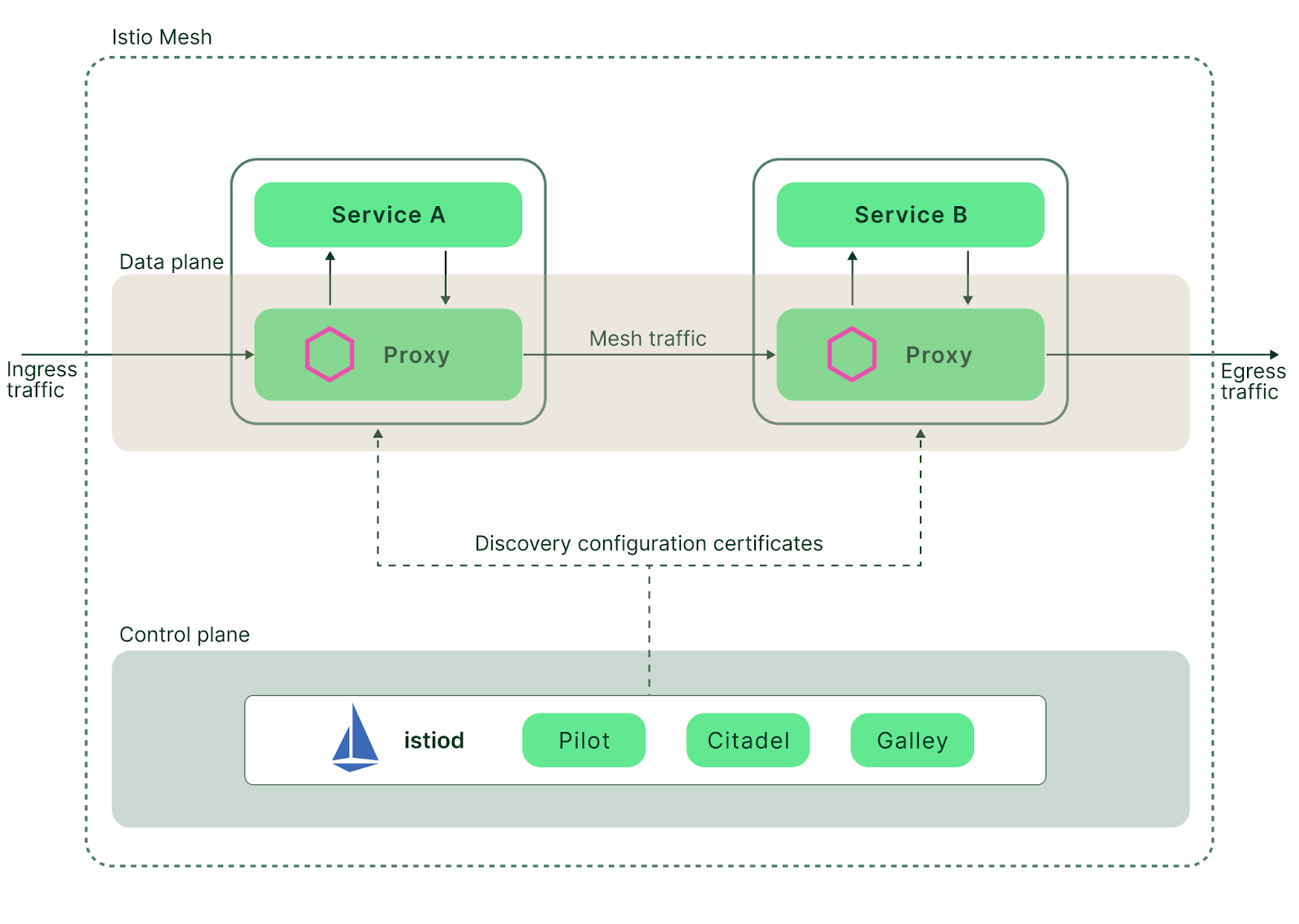
独立的 Envoy
需要注意的是,Envoy 组件是可以单独运行的,就像一个 Nginx 进程一样,只要你为它添加合理的配置。
部署模型
Istio 支持的部署模型比较繁杂,它可以根据多个维度进行分类,包含集群模型/网络模型/控制平面模型/网格模型/租户模型。 任何一个包含 Istio 的生产环境都涉及这几个维度。当然最简单的部署模型就就是单一集群+单一网络+单一控制平面+单一网格+单一租户。 当部署 Istio 时,我们需要根据服务规模和团队数量来规划具体的部署模型。
[!NOTE] 请参考 部署模型 来详细了解 Istio 的部署模型。
更多细节
8.4.2 Ambient Mesh
sidecar 模式的弊病
不管是第一代还是第二代 Service Mesh 技术,都存在着一个令人诟病但不易解决的难题, 那就是 sidecar 模式带来的资源消耗和通信时延问题。根据统计,大部分企业在使用 Istio 的数据平面即 Envoy 时的平均内存开销都在 60M~ 100M 左右, 如果是稍微大一点的规模比如 100 个服务,那么 sidecar 这部分开销就可能接近 10 个 G,并且由于每个代理都会接收所有的服务发现数据(即使不需要), 这会导致代理的内存开销会随着服务规模的增长而呈指数级增长。此外,还有 sidecar 带来的网络多跳和路由计算所增加的网络延迟问题, 平均延迟大致为 3ms~5ms 左右,这对于延迟敏感的业务中可能不会适用。
Istio 的新数据平面模式:No sidecar 的 Ambient Mesh
2022 年 9 月,Istio 官宣了一种新的数据平面模式——Ambient Mesh。它能够在简化操作、保持更广泛的应用程序兼容性和降低基础设施成本的同时, 保持 Istio 的零信任安全、遥测和流量管理等核心功能。最重要的是,它摒弃了传统的 sidecar 部署模式, 转而在每个节点上部署一个零信任的ztunnel代理用来为节点上所有 Pod 提供 mTLS、遥测、身份验证和 L4 授权,它并不会解析 HTTP 流量(L7)。
这种新的平面模式将 Istio 的功能划分为两层:
- 基础层:作为一个必需的安全覆盖层,处理所有应用实例的路由和零信任安全的流量。这一层产生的性能开销较低;
- 具体来说,Istio 会在每个节点上部署一个代理(叫做 ztunnel),用来处理该节点上的所有 L4 流量(如 TCP、UDP 等);
- 应用层:使用一个七层代理来负责处理七层流量,如 HTTP、gRPC 等。这一层产生的性能开销大于基础层;
- 具体来说,Istio 会在集群中新增一个命名空间来部署基于 Envoy 的 Waypoint 代理(以 Pod 形式),由它来处理和转发需要 执行七层流量策略的实例流量;
- Istio 的控制平面会负责 Waypoint 代理策略的下发;
- Waypoint 代理的数量可以根据集群流量规模实现自动缩放。
用户在部署此模式时可能并不需要安装“应用层”,即不需要在实例之间处理七层流量。这样一来就可以按需使用 Istio 提供的功能, 相较 sidecar 模式的无差别全功能提供而言,Ambient Mesh 模式大大减少了 Mesh 架构产生的开销。
尚未准备好用于生产环境
截至目前(2024/3/6),Ambient Mesh 是仍处于 Alpha 阶段的特性,比预期进度(原本预计 2023 年底 Prod Ready)要慢,相关文档还在持续更新中,请持续观望。
8.4.3 安装过程
8.4.3.1 安装
当你准备好开始学习 Istio 时,笔者建议你使用具备高度定制化功能的istioctl命令行工具进行安装,在熟悉安装流程后,再尝试使用 Helm 或其他方式进行安装。 完整的安装指南请参考Istio 安装指南。
[!NOTE] Istio 原生与 Kubernetes 集成(但不绑定),安装 Istio 时会将一些自定义资源安装到 Kubernetes 集群中,因此请提前准备好一个集群以供安装。
安装步骤:
# 1. 在istio发版页面复制需要安装的`istioctl`链接(注意不是istio,以及选择符合节点架构的版本,下面以v1.20.3和linux amd64架构为例)
# https://github.com/istio/istio/releases
# 进入任何一个具有K8s集群管理员权限的主机
$ wget --no-check-certificate \
https://hub.gitmirror.com/?q=https://github.com/istio/istio/releases/download/1.20.3/istioctl-1.20.3-linux-amd64.tar.gz \
-O istioctl.tar
# 解压
$ tar -zxf istioctl.tar && chmod +x istioctl
# 生成即将安装到集群的istio资源的k8s清单文件,稍后用于验证安装是否成功
$ ./istioctl manifest generate > manifest.yaml
# 使用默认配置进行安装
# - 此过程会安装Pod,所以需要拉取远程镜像,可能需要几分钟
$ ./istioctl install
This will install the Istio 1.20.3 "default" profile (with components: Istio core, Istiod, and Ingress gateways) into the cluster. Proceed? (y/N) y
✔ Istio core installed
✔ Istiod installed
✔ Ingress gateways installed
✔ Installation complete
Made this installation the default for injection and validation.查看安装的 istio 部分资源列表:
$ kubectl get deploy,svc,hpa,cm,secret -n istio-system
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/istio-ingressgateway 1/1 1 1 63m
deployment.apps/istiod 1/1 1 1 68m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/istio-ingressgateway LoadBalancer 20.1.124.145 <pending> 15021:30730/TCP,80:32703/TCP,443:32294/TCP 63m
service/istiod ClusterIP 20.1.237.53 <none> 15010/TCP,15012/TCP,443/TCP,15014/TCP 68m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/istio-ingressgateway Deployment/istio-ingressgateway <unknown>/80% 1 5 1 63m
horizontalpodautoscaler.autoscaling/istiod Deployment/istiod <unknown>/80% 1 5 1 68m
NAME DATA AGE
configmap/istio 2 68m
configmap/istio-ca-root-cert 1 5m49s
configmap/istio-gateway-status-leader 0 5m49s
configmap/istio-leader 0 5m49s
configmap/istio-namespace-controller-election 0 5m49s
configmap/istio-sidecar-injector 2 68m
configmap/kube-root-ca.crt 1 68m
NAME TYPE DATA AGE
secret/istio-ca-secret istio.io/ca-root 5 5m51s
# 查看istio安装的自定义资源
$ kubectl -n istio-system get crd
NAME CREATED AT
authorizationpolicies.security.istio.io 2024-03-08T00:43:31Z
bgpconfigurations.crd.projectcalico.org 2024-03-03T05:22:57Z
bgpfilters.crd.projectcalico.org 2024-03-03T05:22:57Z
bgppeers.crd.projectcalico.org 2024-03-03T05:22:57Z
...
# 查看istio安装的role和rolebinding
$ kubectl -n istio-system get role,rolebinding
NAME CREATED AT
role.rbac.authorization.k8s.io/istio-ingressgateway-sds 2024-03-08T00:48:32Z
role.rbac.authorization.k8s.io/istiod 2024-03-08T00:43:32Z
NAME ROLE AGE
rolebinding.rbac.authorization.k8s.io/istio-ingressgateway-sds Role/istio-ingressgateway-sds 68m
rolebinding.rbac.authorization.k8s.io/istiod Role/istiod 73m检查安装结果:
$ ./istioctl verify-install manifest.yaml
1 Istio control planes detected, checking --revision "default" only
✔ HorizontalPodAutoscaler: istio-ingressgateway.istio-system checked successfully
✔ Deployment: istio-ingressgateway.istio-system checked successfully
✔ PodDisruptionBudget: istio-ingressgateway.istio-system checked successfully
...
✔ Service: istiod.istio-system checked successfully
✔ ServiceAccount: istiod.istio-system checked successfully
✔ ValidatingWebhookConfiguration: istio-validator-istio-system.istio-system checked successfully
Checked 15 custom resource definitions
Checked 2 Istio Deployments
✔ Istio is installed and verified successfully
# 查看istio安装的API对象,istio使用它们来完成各项任务
$ kubectl api-resources |grep istio
wasmplugins extensions.istio.io/v1alpha1 true WasmPlugin
istiooperators iop,io install.istio.io/v1alpha1 true IstioOperator
destinationrules dr networking.istio.io/v1beta1 true DestinationRule
envoyfilters networking.istio.io/v1alpha3 true EnvoyFilter
gateways gw networking.istio.io/v1beta1 true Gateway
proxyconfigs networking.istio.io/v1beta1 true ProxyConfig
serviceentries se networking.istio.io/v1beta1 true ServiceEntry
sidecars networking.istio.io/v1beta1 true Sidecar
virtualservices vs networking.istio.io/v1beta1 true VirtualService
workloadentries we networking.istio.io/v1beta1 true WorkloadEntry
workloadgroups wg networking.istio.io/v1beta1 true WorkloadGroup
authorizationpolicies security.istio.io/v1 true AuthorizationPolicy
peerauthentications pa security.istio.io/v1beta1 true PeerAuthentication
requestauthentications ra security.istio.io/v1 true RequestAuthentication
telemetries telemetry telemetry.istio.io/v1alpha1 true Telemetry8.4.3.2 关于 IstioOperator
IstioOperator(官方有时简称为iop)是 Istio 规定的一个自定义资源类型(按 K8s 中的 CRD 格式),它允许用户选择性部署 Istio 服务网格的各个组件。 上节中我们安装的是 istioctl 推荐的默认配置,具体配置内容可通过./istioctl profile dump查看:
# 导入到 iop.yaml 以便后面修改配置再部署
$ ./istioctl profile dump > iop.yaml
$ less iop.yaml
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
components:
base:
enabled: true
cni:
enabled: false
egressGateways:
- enabled: false
name: istio-egressgateway
ingressGateways:
- enabled: true
name: istio-ingressgateway
istiodRemote:
enabled: false
pilot:
enabled: true
...其中的spec.components部分指定了需要安装(enable: true)的 istio 核心组件,默认配置只安装了base,ingressGateways,pilot。 通过以下命令可以查看已安装的 IstioOperator 配置:
$ kubectl -n istio-system get IstioOperator installed-state -o yaml每个组件的作用如下:
- base:istio 核心组件之一,安装控制平面时必需;
- cni:istio 后来添加的一个组件,用于代替原先注入到应用 Pod 的
istio-init容器,以实现应用容器的流量劫持功能;- 具体来说,在部署应用 Pod 时,istio 不再注入
istio-init容器,而是使用 CNI 插件来为应用 Pod 配置网络。 - 属于一项较为先进的功能,本文暂不使用;
- 具体来说,在部署应用 Pod 时,istio 不再注入
- ingressGateways:网格流量的入站网关,用于管控网格的所有入站流量。比如 TLS 设置和路由策略等;
- 常用组件,可用于替代 K8s 的 ingress API;
- egressGateways:网格流量的出站网关,与 ingress 网关对称。用于管控网格内的所有出站流量;
- 非必需组件,适用于以下场景:
- 管理员需要严格管控网格内某些应用的出站流量,这是一种安全需求;
- 集群内的节点没有公网 IP,通过安装 egress 网关并为其配置公网 IP,可以使网格内的流量以受控方式访问外部服务;
- 非必需组件,适用于以下场景:
- istiodRemote:在受外部控制面管理的从集群中安装 istio 时需要的组件,可以参考使用外部控制平面安装 Istio;
- pilot:istio 核心组件之一,负责网格内的服务发现和配置管理;
- 服务发现:跟踪 K8s 集群中的 Service 资源变化,并实时下发给各个 Envoy 代理,避免各代理转发流量到失效主机;
- 配置管理:包括网格内的路由规则和流量规则等,它们以 K8s CRD 的形式存储在集群中。
- pilot 划分为两个组件:
- pilot-discovery:位于 istiod 内部,负责发现集群内的配置变化和 Service 端点变化,并通过 gRPC stream 连接实时下发给 Envoy 代理;
- pilot-agent:位于 Envoy 代理内部,负责从 pilot-discovery 获取最新的证书、策略配置以及服务端点,并将其注入到 Envoy 代理的配置文件中;
其他关于 IstioOperator 配置的操作命令:
# 查看内置的配置列表,查看每个配置的介绍:https://istio.io/latest/zh/docs/setup/additional-setup/config-profiles/
# 实战中根据需求选择哪个档位。
$ istioctl profile list
Istio configuration profiles:
default
demo
empty
minimal
openshift
preview
remote
# 查看demo档位的配置内容
$ istioctl profile dump demo
# 查看配置的某个部分
$ istioctl profile dump --config-path components.pilot demo
# 查看不同档位配置间的差异,例如default和demo
$ istioctl profile diff default demo
# 卸载istio
$ istioctl uninstall --purge && kubectl delete ns istio-system最后,IstioOperator 自有一套配置规范,请查阅IstioOperator Options。
8.4.4 Envoy 介绍
Envoy 是一个由 C++开发的、开源的、面向大型现代服务架构设计的高性能L7 代理和通信总线。它于 2016 年 8 月开源,2017 年 9 月捐献给 CNCF 开始孵化, 后在 2018 年 11 月成为 CNCF 继 Kubernetes 与 Prometheus 之后第三个毕业的项目。Envoy 的定位是做一个高性能的通用代理,可以与任何语言构建的服务通信, 它能够提供服务发现、负载均衡、TLS 终止、L3(TCP/UDP 等) & HTTP/2 & gRPC 代理、熔断、追踪、健康检查、限流等丰富的网络通信转发功能。
Envoy 还支持代理 MongoDB、Redis 和 Postgres 协议。
虽然 Istio 采用其作为默认的数据平面代理,但 Envoy 并不与 Istio 绑定。Envoy 通常以 sidecar 模式部署在应用 Pod 中,但也支持作为前端/边缘代理角色部署,就像网关一样。 参考此页面了解 Envoy 如何作为前端代理进行工作。
显著优势
- 性能:Envoy 是 C++开发的高性能 L7 代理;
- 丰富特性:通过配置各类过滤器执行丰富的流量和路由策略;
- 支持多种协议:支持 HTTP/1.1、HTTP/2、gRPC、MongoDB、Redis、MySQL、Postgres、DNS 等协议;
- 动态配置:通过 xDS API 协议动态接收来自控制面下发的配置,实现免重启更新配置。同时也支持静态配置,在作为前端/边缘代理时会用到。
- xDS(
* Discovery Service的缩写),其包含 L(istener)DS、C(luster)DS、R(oute)DS、E(ndpint)DS、S(ecret)DS 等在内的多个发现服务。
- xDS(
四大组件
Envoy 内部有四个主要组件,下面根据工作顺序按序介绍:
- 监听器(Listener):类似 Nginx 的监听端口,接收来自外部的 TCP 入站连接请求;
- 过滤器(Filter):处理监听器接收到的入站请求所传输的流量;
- 主要是通过预配置的各种过滤器进行工作,可以进行请求路由、速率限制等操作;多个过滤器之间通过链式配置和工作;
- 丰富的过滤器类别是 Envoy 的核心功能优势。
- 路由(Router):指定如何将入站连接请求路由到 Envoy 代理内部配置的 Cluster,这是一个流量出站步骤;
- 集群(Cluster):这里的集群不同于传统意义上的集群,而是指流量转发的目的地址(类似 Nginx 的 upstream,即转发的后端地址),同时可以配置负载均衡等策略。
常用术语
- 主机(Host):一个具有网络通信能力的端点,例如服务器、移动智能设备等,而这里的 host 通常代表上游服务
- 集群(Cluster):集群是 Envoy 连接到的一组逻辑上相似的端点;在 v2 中,RDS 通过路由指向集群,CDS 提供集群配置,而 Envoy 通过 EDS 发现集群成员,即端点(Endpoint);
- 下游(Downstream):下游主机连接到 Envoy,发送请求并接收响应,它们是 Envoy 的客户端;
- 上游(Upstream):上游主机接收来自 Envoy 的连接和请求并返回响应,它们是 Envoy 代理的后端服务器,可能是容器、虚拟机、服务器;
- 端点(Endpoint):端点即上游主机,是一个或多个集群的成员,可通过 EDS 发现;
- 侦听器(Listener):侦听器是能够由下游客户端连接的命名网络位置,例如端口或 unix 域套接字等;
- 子集(Subset):子集是具有相同标签的端点的逻辑分组,例如金丝雀发布时通常会根据版本标签配置两个不同版本的服务子集, 然后为两个子集分配不同的流量权重(可 能是1:9);
- 位置(Locality):上游端点运行的区域拓扑,包括地域、区域和子区域等;
- 管理服务器(Management Server):实现 v3 API 的服务器,它支持复制和分片,并且能够在不同的物理机器上实现针对不同 xDS API 的 API 服务。Istio 中指控制面;
- 地域(Region):区域所属地理位置;
- 区域(Zone):AWS 中的可用区(AZ)或 GCP 中的区域等;
- 子区域:Envoy 实例或端点运行的区域内的位置,用于支持区域内的多个负载均衡目标;
- Mesh 和 Envoy Mesh:指代服务网格,由多个基于 envoy 代理的 sidecar 构成。
[!TIP] 如何快速理解上下游概念?
- 一般只对代理这个角色讨论上下游概念;
- 进入代理的请求即是下游请求,而代理再转发的则是上游请求。例如 Nginx 反代,Client 发出的是下游请求,Nginx 转发至 Server 的是上游请求, 所以 Nginx 配置中使用
upstream关键字来定义 Server 端点;- 注意:理解此概念后才能在后续的演示练习中游刃有余的分析 Envoy 日志。
8.4.5 使用演示
8.4.5.1 sidecar 注入的两种方式
Istio 通过为对象添加标签(Label)的方式来实现 sidecar 注入,具体分为自动和手动两种:
- 自动注入:通过为 K8s 集群中的命名空间(Namespace)对象添加 Istio 识别的特定标签来实现自动注入;
- 具体来说,当 K8s 集群中的命名空间对象被添加了
istio-injection=enabled标签时,任何新的 Pod 都将在创建时自动添加 sidecar。 - 这种注入对工作负载是完全无感知的,它不会修改资源模板;
- 若不希望 Pod 被注入 sidecar,则可以为 Pod 对象添加
sidecar.istio.io/inject="false"注解(此注解优先级高于 命名空间标签);
- 具体来说,当 K8s 集群中的命名空间对象被添加了
- 手动注入:通过手动执行命令实现 sidecar 注入
- 具体来说,执行
istioctl kube-inject -f samples/sleep/sleep.yaml命令即可将 sidecar 注入到指定的 Pod - 以上命令使用 istio 安装到集群的配置进行注入,也可以使用本地配置,具体方法参考手动注入;
- 由于对资源模板的入侵性,手动注入仅在特定情况下使用。
- 具体来说,执行
[!NOTE] 不要在 Pod 定义中包含
hostNetwork:true,否则将不会注入 sidecar。此外,kube-system或kube-public命名空间 中的 Pod 也不会被注入 sidecar。
本文仅介绍更常用的自动注入方式,操作步骤如下:
# 为命名空间设置特定标签,以 default 为例
$ kubectl label namespace default istio-injection=enabled --overwrite
namespace/default labeled
$ kubectl get ns default --show-labels
NAME STATUS AGE LABELS
default Active 2m2s istio-injection=enabled,kubernetes.io/metadata.name=default
# 删除标签命令:kubectl label namespace default istio-injection-添加标签后,新部署的 Pod 都会自动注入 sidecar,但不会修改资源清单。
8.4.5.2 部署 Pod 进行验证
这里仍然使用第一节中只定义了一个常规容器的 deployment.yaml 模板进行验证,注意还需要部署相关的几个资源:
- configmap.yaml
- secret.yaml
- service.yaml
- Istio 的 mTLS 仅在定义了 service 的工作负载上生效,所以必须部署 service。
操作步骤如下:
# 1. 部署configmap、secret以及service,步骤略。
# 2. 部署deployment
$ kubectl apply -f deployment.yaml
# 3. 可以看到 READY 处的2/2表示Pod内部有2个容器正在运行
$ kubectl get po -l app=go-multiroute
NAME READY STATUS RESTARTS AGE
go-multiroute-b6fcdf544-7xfn7 2/2 Running 0 2m40s
go-multiroute-b6fcdf544-dqncx 2/2 Running 0 5m27s
# 4. 查看Pod事件,可以看到Pod启动过程中创建了注入的istio-init和istio-proxy容器,加上原本的 go-multiroute 一共3个容器
# -- 但其中的istio-init是初始化容器
$ kubectl describe po go-multiroute-b6fcdf544-7xfn7 |grep Events: -A 15
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 5m16s default-scheduler Successfully assigned default/go-multiroute-b6fcdf544-7xfn7 to k8s-node1
Normal Pulled 2d3h kubelet Container image "docker.io/istio/proxyv2:1.20.3" already present on machine
Normal Created 2d3h kubelet Created container istio-init
Normal Started 2d3h kubelet Started container istio-init
Normal Pulled 2d3h kubelet Container image "docker.io/leigg/go_multiroute:v1" already present on machine
Normal Created 2d3h kubelet Created container go-multiroute
Normal Started 2d3h kubelet Started container go-multiroute
Normal Pulled 2d3h kubelet Container image "docker.io/istio/proxyv2:1.20.3" already present on machine
Normal Created 2d3h kubelet Created container istio-proxy
Normal Started 2d3h kubelet Started container istio-proxy
# 5. 查看istio正在代理的所有Pod,包括每个Pod的xDS同步状态,可添加 -n 指定 namespace
$ ./istioctl proxy-status
NAME CLUSTER CDS LDS EDS RDS ECDS ISTIOD VERSION
go-multiroute-b6fcdf544-7xfn7.default Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-78478fdc7-qmzbb 1.20.3
go-multiroute-b6fcdf544-dqncx.default Kubernetes SYNCED SYNCED SYNCED SYNCED NOT SENT istiod-78478fdc7-qmzbb 1.20.38.4.5.3 Istio 特性之 mTLS
Istio 提供诸多特性,这里将介绍如何使用其中的mTLS(双向 TLS)特性。 启用 mTLS 可以实现 sidecar 之间的双向身份认证、传输流量加密,可以避免中间人攻击,提高传输安全性。 部署后,Istio 的控制面可以自动完成将要过期的 sidecar 证书轮换。 要启用 mTLS,必须启动两个不同的服务进行互相通信,前面已经部署了一个go-multiroute服务, 它通过 configmap 提供了两个 HTTP 接口/route1和/route2,这里将其作为被调用端, 然后我们再启动一个调用端服务istio_client_test,构建和上传镜像的步骤略,相关清单如下:
操作步骤如下:
# 为了避免网络策略的干扰,先删除之前部署的默认拒绝 networkpolicy
kubectl delete networkpolicy block-internal-all-egress
kubectl delete networkpolicy deny-all-ingress
# 部署调用端Pod
kubectl apply -f istio_client_test_pod.yaml
# 查看启动日志(启动时发起调用)
$ kubectl logs istio-client-test-$POD_ID
2024/03/08 08:07:22 status:200 text: [v1] Hello, You are at /route1, Got: route1's content
# 然后可在istio-client-test中的Pod上进行抓包测试。
# - 使用tcpdump抓取默认网卡上来源是3000端口的tcp数据流,可以观察到包含"Hello"字眼的http响应明文
# - (开始抓包后,需要同步在相同的Pod上的另一个容器中执行curl访问go-multiroute服务:kubectl exec -it istio-client-test-$POD_ID -c istio-client-test -- curl go-multiroute:3000/route1)
# - (执行curl访问后,这边应立即可以观察到控制台输出相关tcp数据)
$ kubectl exec -it istio-client-test-$POD_ID -c tcpdump -- tcpdump -nX tcp src port 3000
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
09:43:58.668073 IP 20.2.36.112.3000 > 20.2.36.117.60022: Flags [P.], seq 3671286507:3671287547, ack 2394647540, win 291, options [nop,nop,TS val 2452817 ecr 2452816], length 1040
...
0x0040: 204f 4b0d 0a64 6174 653a 2053 756e 2c20 .OK..date:.Sun,.
0x0050: 3130 204d 6172 2032 3032 3420 3039 3a34 10.Mar.2024.09:4
0x0060: 333a 3538 2047 4d54 0d0a 636f 6e74 656e 3:58.GMT..conten
...
0x00e0: 643a 2073 6964 6563 6172 7e32 302e 322e d:.sidecar~20.2.
0x00f0: 3336 2e31 3132 7e67 6f2d 6d75 6c74 6972 36.112~go-multir
0x0100: 6f75 7465 2d62 3666 6364 6635 3434 2d62 oute-b6fcdf544-b
0x0110: 7a7a 7237 2e64 6566 6175 6c74 7e64 6566 zzr7.default~def
0x0120: 6175 6c74 2e73 7663 2e63 6c75 7374 6572 ault.svc.cluster
0x0130: 2e6c 6f63 616c 0d0a 782d 656e 766f 792d .local..x-envoy-
0x0140: 7065 6572 2d6d 6574 6164 6174 613a 2043 peer-metadata:.C
0x0150: 6945 4b44 6b46 5155 4639 4454 3035 5551 iEKDkFQUF9DT05UQ
...
0x03e0: 5555 5344 786f 4e5a 3238 7462 5856 7364 UUSDxoNZ28tbXVsd
0x03f0: 476c 7962 3356 305a 513d 3d0d 0a73 6572 Glyb3V0ZQ==..ser
0x0400: 7665 723a 2069 7374 696f 2d65 6e76 6f79 ver:.istio-envoy
0x0410: 0d0a 0d0a 4865 6c6c 6f2c 2059 6f75 2061 ....Hello,.You.a
0x0420: 7265 2061 7420 2f72 6f75 7465 312c 2047 re.at./route1,.G
0x0430: 6f74 3a20 726f 7574 6531 2773 2063 6f6e ot:.route1's.con
0x0440: 7465 6e74 tent现在为 go-multiroute 服务配置双向认证策略(mTLS):peer_authn.yaml, 它同样是以 K8s 资源清单的形式部署,该资源的kind为PeerAuthentication。操作步骤如下:
# 部署mTLS策略
$ kubectl apply -f peer_authn.yaml
peerauthentication.security.istio.io/go-multiroute created
# 可使用缩写形式:pa
$ kubectl get peerauthentications
NAME MODE AGE
go-multiroute STRICT 4m42s部署后,访问 go-multiroute 服务就必须遵循策略中配置的强制(STRICT)双向 TLS 通信模式。 这可以通过上面使用过的 tcpdump 抓包方式来验证,抓取结果将是各种乱码,无法观察到人眼可读的明文。
启用 mTLS 特性需要注意两点:
- 默认情况(没有任何 mTLS 配置)下,Istio 会为所有网格(注入了 sidecar 的)服务启用自动 mTLS(
PERMISSIVE模式), 即对网格服务发送 TLS 流量,对非网格服务发送明文流量。在迁移到全局STRICT模式前,确保没有网格服务正在收发明文流量(避免造成中断); - 在迁移到全局
STRICT模式前,确保所有指向网格服务的DestinationRule配置tls.mode为ISTIO_MUTUAL,避免产生 503; - 建议以命名空间的粒度逐步启用全局 mTLS;
- 若要关闭 mTLS,直接删除策略是不起作用的,必须将策略改为
DISABLE模式然后应用,这样才会生效。 同理,为了避免影响正在运行的服务,需要先设置策略为PERMISSIVE模式进行过渡,一段时间后再切换到DISABLE模式; - Istio 支持为纯 TCP 或基于 TCP 的 HTTP、gRPC 等协议提供 mTLS 支持;Istio 不会代理 UDP 协议(但 Envoy 本身支持), 即应用容器的 UDP 数据报文不会经过 sidecar 容器的网络栈,所以也不需要在 Istio 的流量策略中配置应用的 UDP 端口;
其他建议和 Tips:
- 可以设置根命名空间
istio-system的默认 mTLS 模式为STRICT以影响整个网格范围,使用模板 peer_authn_default.yaml。 - 将模板中的
namespace字段改为非根命名空间以影响特定命名空间; - 策略优先级:工作负载级别 > 命名空间级别 > 根命名空间级别;
对等认证即 mTLS 是 Istio 提供的两个认证特性之一,另一个认证特性是请求认证(
RequestAuthentication),它使用 JWT 技术实现针对 HTTP 请求的认证。 由于篇幅所限和使用频率不高,本文不会详述, 请参考请求认证。
清理
kubectl delete -f peer_authn.yaml8.4.5.4 Istio 特性之授权
Istio 通过预先安装到 Kubernetes 集群中的 AuthorizationPolicy 自定义 API 资源来提供细粒度的授权功能,其具有如下优点和特性:
- 实现拒绝或允许指定的不同
通信源之间的流量访问; 通信源可以是一组 Pod/IP 块/服务账号,甚至是一整个命名空间;- 可以限制具体执行的 HTTP 方法,如 GET、POST 等;
- 可以限制具体访问的 HTTP 路由,如
/get_order; - 大部分维度支持排除匹配,比如
to.operations.notPaths: /get_order表示匹配除了/get_order以外的 HTTP 路由; - 可以设置工作负载、命名空间或网格维度的默认授权策略,例如默认拒绝或允许范围内的所有 HTTP 通信;
- 可以为策略设置附加条件,例如若要拒绝通信源 A 到 B 之间的访问,还要求 HTTP 请求的 Header 中必须携带
version: v1键值对; - 支持 HTTP 1.1/2 以及 HTTPS
[!WARNING] Istio 的 AuthorizationPolicy API 不能取代 K8s 内置的 NetworkPolicy API。这是因为 Istio 的授权建立在 sidecar 的基础上, 而用户可以移除 sidecar。若要(对部分关键服务)实现绝对的流量安全,请搭配使用 K8s 内置的 NetworkPolicy API。
一个 AuthorizationPolicy 资源清单由以下三部分组成:
- selector(选择器):匹配一组要执行策略的目标;
- action(动作):要执行的动作,可以
DENY或ALLOW,另外还支持CUSTOM和AUDIT动作; - rules(规则集合):什么条件下控制谁到谁的访问,其中每个元素由三部分组成:
from字段指定请求来源,支持指定命名空间/认证身份/服务账号/IP 块;to字段指定请求方法、路由和端口;when字段指定条件(触发时机),参考Istio 授权策略之when字段;
授权引擎的执行过程
- 若范围内没有创建任何策略,则允许;
- 按照动作
CUSTOM->DENY->ALLOW的顺序依次匹配策略,这个过程中只要成功匹配一个拒绝策略则立即执行; - 若没有创建任何
ALLOW策略,则允许; - 最后,在定义了
ALLOW策略的情况下却没有匹配到任何一个允许策略则拒绝。
在普通 TCP 协议上使用 Istio 授权
Istio 授权策略支持纯 TCP 和基于 TCP 的其他协议,若在针对纯 TCP 工作负载的授权策略中配置了仅 HTTP 支持的字段如methods等, 则 Istio 将忽略这些字段,但不影响其他字段的匹配行为。注意,所有授权策略都将下发给 Envoy 执行,所以这个执行过程是高效的。 仅 HTTP 支持的字段如下:
source.request_principalsoperation部分中的hosts、methods和paths字段when.key中的request.headers、request.auth.claims/principal/audiences/presenter
为了更接近最佳实践和实际环境,演示将完成以下目标(提供模板):
- 创建 default 空间下的默认拒绝策略;
- authz-allow-nothing.yaml;
- 注意,这不会影响 UDP 通信;
- 创建一个允许策略,允许①满足条件位于
other_ns命名空间【或】服务帐户为cluster.local/ns/default/sa/default的工作负载 通过 ②GET和POST方法访问③default 命名空间下与app: go-multiroute标签匹配的工作负载提供的④以/route为前缀的路由,附加条件⑤是 HTTP Header 中包含键值对version: v1;
操作步骤如下:
# 首先部署默认拒绝策略
$ kubectl apply -f authz-allow-nothing.yaml
authorizationpolicy.security.istio.io/allow-nothing created
# 此时 istio-client-test 测试访问 go-multiroute 会得到明确的拒绝访问提示!
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v1" go-multiroute:3000/route1
RBAC: access denied
# 部署第二个策略
$ kubectl apply -f authz-allow-to-go-multiroute.yaml
authorizationpolicy.security.istio.io/allow-to-go-multiroute created
# 查看default空间中的授权策略列表
$ kubectl get authorizationpolicies
NAME AGE
allow-nothing 2m
allow-to-go-multiroute 2m
# 可以访问,因为满足 rules 中所要求的各种条件
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v1" go-multiroute:3000/route1
[v1] Hello, You are at /route1, Got: route1's content
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v1" go-multiroute:3000/route2
[v1] Hello, You are at /route2, Got: route2's content
$ kubectl exec -it istio-client-test-$POD_ID -- curl -X POST -H "version: v1" go-multiroute:3000/route2
[v1] Hello, You are at /route2, Got: route2's content
# --------- 观察下面被拒绝的情况 -----------
# - 拒绝访问(header不符合)
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v2" go-multiroute:3000/route1
RBAC: access denied
# - 拒绝访问(method不符合)
$ kubectl exec -it istio-client-test-$POD_ID -- curl -X PATCH -H "version: v1" go-multiroute:3000/route1
RBAC: access denied
# - 拒绝访问(路由不符合)
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v1" go-multiroute:3000
RBAC: access denied
# 修改istio-client-test使用的ServiceAccount为`sa-test`(创建SA的步骤略)
$ kubectl patch deployment istio-client-test -p '{"spec": {"template": {"spec": {"serviceAccountName": "sa-test"}}}}'
deployment.apps/istio-client-test patched
# ~等待deployment内Pod更新完毕
# - 拒绝访问(ServiceAccount不符合)
$ kubectl exec -it istio-client-test-$POD_ID -- curl -H "version: v1" go-multiroute:3000/route1
RBAC: access denied
# (为了方便下一节的演示,请回滚这次patch)[!TIP] 若你已为网格启用了全局
STRICT模式的 mTLS,那么你可以在鉴权层进行额外检查,即当主体为空时拒绝通信,参考 authz-deny-emptyid.yaml 。
最后,本节中的示例并未列出可用的全部字段,如有兴趣请查看Istio 授权策略规范。其他可供参考的文档或模板:
清理
kubectl delete -f authz-allow-nothing.yaml
kubectl delete -f authz-allow-to-go-multiroute.yaml8.4.5.5 Istio 特性之流量管理
Istio 的流量管理可以实现以下功能:
- 智能路由:对到达 K8s Service 的 HTTP 流量根据权重/HTTP-Header/sourceLabels 等维度进行分流,基于此可轻松实现灰度发布、A/B 测试、金丝雀发布等部署策略;
- 服务发现、健康检查:Envoy 代理会主动发现需要关心的后端服务的端点列表,并通过健康检查移除失效的端点;
- 负载均衡:Envoy 代理会根据预设的负载均衡算法(如随机、轮询、加权轮询和最少连接等)将请求均匀地分发到后端服务;
- 在选择具体的负载均衡算法之前,Envoy 支持三种类型的负载均衡器(不同类型支持不同算法):
- simple:基于常用负载均衡算法的简单负载均衡
- consistentHashLB:基于一致性哈希算法的负载均衡
- localityLbSetting:基于地域的本地性负载均衡
- 在选择具体的负载均衡算法之前,Envoy 支持三种类型的负载均衡器(不同类型支持不同算法):
- 服务弹性:支持为后端配置限速、熔断、超时和重试等弹性能力;
- 故障注入:支持对后端服务进行故障注入,模拟服务故障,以便进行服务弹性测试。也可用来实现手动熔断的目的;
- 流量镜像:也称为影子流量,用于将实时流量的副本发送到另一组后端,一般用于线上流量分析、统计和程序测试等用途;
- Ingress 和 Egress:控制 Istio 服务网格的入站流量和入站流量,前者可以替代 K8s 内置的 Ingress。
以上这些特性是通过 Istio 预安装的 VirtualService 和 DestinationRule 两个 K8s API 资源实现的,它们分别定义了路由规则和目标规则。 通俗来说,VirtualService定义了如何进行路由(How),DestinationRule定义了路由到哪儿(Where), 一定程度上是前者引用后者的关系。
[!NOTE] VirtualService 和 DestinationRule 资源并不是强绑定的关系,它们可以各自定义并独立工作, 仅在定义 subset(子集)时前者才会依赖后者。但只有将二者结合使用才能充分应用 Istio 丰富的流量管理特性。
为了尽可能模拟实际环境,本节演示内容将增加一个名为 go-multiroute-v2 的服务版本模拟金丝雀发布, 它与之前部署的版本区别在于模板中定义了不同的环境变量VERSION,相关资源如下:
新版本的工作负载的部署步骤略。本次演示将实现以下功能:
- 智能路由:对发送到 Service:go-multiroute 的流量进行按比例分流,即 Deployment
go-multiroute和go-multiroute-v2分别接收 80%和 20%的流量;同时将 HTTP Header 中携带test-version: v2的请求全部路由到go-multiroute-v2; - 负载均衡:分流之后,对发送到每个 Deployment 控制下的 Pod 实例的流量进行负载均衡,使用随机算法;
- 服务弹性:对发送到 Service:go-multiroute 的流量限制最多 5 个请求的并发数,并配置熔断、超时机制;
新增下面的 YAML 清单:
操作步骤如下:
# 部署流量策略
$ kubectl apply -f route-destinationrule.yaml -f route-virtualservice.yaml
destinationrule.networking.istio.io/go-multiroute created
virtualservice.networking.istio.io/go-multiroute created
# 现在进入client pod验证各项配置是否生效
$ kubectl exec -it istio-client-test-$POD_ID -- sh
# 8比2的权重分流:访问10次,观察返回结果(每个结果的前4个字符表示响应的deployment版本)
/ $ for i in $(seq 1 10); do curl -s go-multiroute:3000/route1 && sleep 1 && echo; done
[v2] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
[v1] Hello, You are at /route1, Got: route1's content
# 测试特定header的分流
/ $ for i in $(seq 1 5); do curl -s -H "test-version: v2" go-multiroute:3000/route1 && sleep 1 && echo; done
[v2] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
[v2] Hello, You are at /route1, Got: route1's content
# 测试分流后的负载均衡:轮询(可观察到v1版本的ip分布是均衡的)
/ $ for i in $(seq 1 10); do curl -s go-multiroute:3000/get_ip && sleep 1 && echo; done
[v2] Hello, Your ip is 20.2.36.111
[v2] Hello, Your ip is 20.2.36.112
[v1] Hello, Your ip is 20.2.36.113
[v1] Hello, Your ip is 20.2.36.114
[v1] Hello, Your ip is 20.2.36.113
[v1] Hello, Your ip is 20.2.36.114
[v1] Hello, Your ip is 20.2.36.113
[v2] Hello, Your ip is 20.2.36.111
[v1] Hello, Your ip is 20.2.36.114
[v1] Hello, Your ip is 20.2.36.113
# 测试超时
# - 由于接口 /test_timeout 会等待3s再返回,超过了策略中的2s,所以会超时
/ $ for i in $(seq 1 3); do curl -s go-multiroute:3000/test_timeout && echo " $(date)"; done
upstream request timeout Thu Mar 14 05:47:29 UTC 2024
upstream request timeout Thu Mar 14 05:47:30 UTC 2024
upstream request timeout Thu Mar 14 05:47:31 UTC 2024
# 测试熔断
# - 由于Service:go-multiroute目前的端点较多(2个Deployment共4个Pod对应4个端点),为了方便观察测试结果,先删除deployment-v1(操作略)。
# - 现在只剩下deployment-v2,其中Pod副本数为2,将其改为1,操作略。而且负载均衡策略为轮询,根据如下熔断策略计算:
# outlierDetection: # 定义熔断策略
# consecutive5xxErrors: 3 # 指定连续多少个 5xx 错误会导致端点被剔除,默认5,0表示禁用(但是时间窗口未知)
# interval: 1s # 熔断检测间隔,默认10s,要求>=1ms
# baseEjectionTime: 10s # 初始的端点剔除时间,支持单位 ms s m h,默认30s,要求>=1ms
# maxEjectionPercent: 100
# 即最少并发3(=1x3)个请求后,将触发熔断,10s后恢复(命令尾部的&表示并发)
# - 观察3个请求响应状态码均为500,因此会立即触发熔断,下一步进行验证
/ $ seq 3 | xargs -I {} sh -c 'curl -s -H "test-version:v2" -H "need_500:true" http://go-multiroute:3000/test_circuit_breaker &' && echo $(date)
Fri Mar 15 06:17:41 UTC 2024
[v2] test_circuit_breaker returned 500
[v2] test_circuit_breaker returned 500
[v2] test_circuit_breaker returned 500
# 立即执行如下命令验证熔断策略已触发
# - 下面的命令是以1次/1s的频率顺序执行12个HTTP请求
# - 观察前几个响应内容是来自Envoy的no healthy upstream,说明熔断策略已触发,并在约10s后恢复(之后又触发)
/ $ seq 12 | xargs -I {} sh -c 'curl -s -H "test-version:v2" http://go-multiroute:3000/test_circuit_breaker && echo " $(date)" && sleep 1'
no healthy upstream Fri Mar 15 06:17:44 UTC 2024
no healthy upstream Fri Mar 15 06:17:45 UTC 2024
no healthy upstream Fri Mar 15 06:17:46 UTC 2024
no healthy upstream Fri Mar 15 06:17:47 UTC 2024
no healthy upstream Fri Mar 15 06:17:48 UTC 2024
no healthy upstream Fri Mar 15 06:17:49 UTC 2024
no healthy upstream Fri Mar 15 06:17:50 UTC 2024
[v2] test_circuit_breaker returned 500
Fri Mar 15 06:17:51 UTC 2024 <--- 约10s后恢复!
[v2] test_circuit_breaker returned 500
Fri Mar 15 06:17:52 UTC 2024
[v2] test_circuit_breaker returned 500
Fri Mar 15 06:17:53 UTC 2024
no healthy upstream Fri Mar 15 06:17:54 UTC 2024
no healthy upstream Fri Mar 15 06:17:55 UTC 2024
# 测试最大并发数①
# - 为了方便测试,这里暂时注释熔断策略配置,以及将deployment-v2的副本数改为1(操作略)
# - 进入默认容器内进行并发访问(配置最大并发数5,测试并发数8,结果中5个响应成功,3个超时)
/ $ seq 8 | xargs -I {} sh -c 'curl -s http://go-multiroute:3000/test_limiter &'
[v1] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
upstream request timeoutupstream request timeoutupstream request timeout
# 测试最大并发数②
# - 修改配置中的最大并发数为3,操作略
# - 可观察到测试并发数6,结果中3个响应成功,3个超时)
# - 之所以超时是因为该接口默认sleep 1s,对于非并发执行的请求,其响应耗时必将超过1s,则触发 VirtualService 中的timeout: 1200ms
/ $ seq 6 | xargs -I {} sh -c 'curl -s -H "test-version:v2" http://go-multiroute:3000/test_limiter &'
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
[v2] Hello, You are at /test_limiter, Got: test_limiter's content
upstream request timeoutupstream request timeoutupstream request timeout完整的金丝雀发布
通过VirtualServiceAPI 可以实现将流量路由到不同版本的服务(Pod 组),这是第一步;分流以后,我们需要观察一段时间内 v2 版本服务的请求处理是否正常,这是第二步; 若不正常,则需要回滚,将流量全部路由回 v1 版本。若基本正常,则可以进行第三步,即修改VirtualService清单中的路由规则, 将所有流量仅路由到 v2 版本即可;最后,继续观察一段时间,确保 v2 版本服务稳定,则可以删除 v1 版本服务了。
清理
$ kubectl delete -f route-destinationrule.yaml -f route-virtualservice.yaml
destinationrule.networking.istio.io "go-multiroute" deleted
virtualservice.networking.istio.io "go-multiroute" deleted8.4.5.6 流量管理之 Ingress 网关
与 K8s 内置的 Ingress 类似,如果你按照前面的安装步骤Istio 在安装时也部署了一个 Ingress 网关(本质是 Envoy)来管理集群的入站流量,它可以用来替换 K8s 内置的 Ingress, 好处是它具有更细粒度的控制功能。
[!NOTE] K8s Ingress 也可与 Istio 网格协同工作。
如果没有安装 Ingress 网关,使用istioctl install命令安装即可。使用如下命令检查是否安装:
# 部署后,你可以使用 kubectl get deploy istio-ingressgateway -n istio-system -o yaml > ingress-deploy.yaml 导出清单来独立管理网关
$ kubectl get deploy,svc,hpa -n istio-system |grep gateway -B 1
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/istio-ingressgateway 1/1 1 1 3d7h
--
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/istio-ingressgateway LoadBalancer 20.1.185.158 <pending> 15021:31132/TCP,80:31227/TCP,443:30215/TCP 3d7h
--
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/istio-ingressgateway Deployment/istio-ingressgateway <unknown>/80% 1 5 1 3d7可见 Ingress 网关是以 Deployment 形式部署,并且还创建了一个 HPA 以供 Pod 副本弹性伸缩。最后,Istio 为 Ingress 网关创建了一个 LoadBalancer 类型的 Service,将其对外暴露。 但由于笔者的集群是自建的,所以无法为 LoadBalancer 类型的 Service 分配一个外部的公网 IP,但我们可以使用它的 CLUSTER-IP 字段即20.1.185.158来做集群内的访问测试。
与 K8s Ingress 不同的是,Istio Ingress 网关的编程方式是一个 Gateway 资源绑定一个 VirtualService 资源的组合。当然也非常简单, 你可以通过下面的演示来了解具体细节。
本节演示要实现的目标只有一个:将Service: go-multiroute的 3000 端口通过 Ingress 对外暴露到 80 和 443 端口, 使用证书对应的域名是:*.foobar.com,然后在任一集群节点上进行访问测试。 新增的资源清单文件如下:
具体操作步骤如下:
# 1. 因为使用了HTTPS协议,所以先为服务生成一个自签名证书
# - 1.1 生成根私钥和根证书
openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 \
-subj '/O=example Inc./CN=example.com' \
-keyout ca.key -out ca.crt
openssl x509 -noout -text -in ca.crt # check crt
# - 1.2 使用根证书和根私钥为泛域名 *.foobar.com 生成私钥和证书(foobar.key | foobar.crt)
openssl genrsa -out foobar.key 2048
openssl req -key foobar.key -new -out foobar.csr -subj '/C=US/ST=California/CN=*.foobar.com/O=My Company'
openssl x509 -req -in foobar.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out foobar.crt -days 365
# 2. 创建网关使用的secret(只能在istio-system空间下创建才能被找到)
kubectl create secret tls cert-foobar --cert=foobar.crt --key=foobar.key -n istio-system
# - 使用istioctl查看网关Pod关联的secret(最后一个参数是<POD>.[ns]的格式)
$ ./istioctl pc secret istio-ingressgateway-d4db74f5b-l44h4.istio-system
RESOURCE NAME TYPE STATUS VALID CERT SERIAL NUMBER NOT AFTER NOT BEFORE
default Cert Chain ACTIVE true 653e6e499c6dd8ac7309498fa7ee7dd5 2024-03-17T12:28:45Z 2024-03-16T12:26:45Z
kubernetes://cert-foobar Cert Chain ACTIVE true aaec8a8aee3fc3f9 2024-04-15T15:49:40Z 2024-03-16T15:49:40Z
ROOTCA CA ACTIVE true f915f3f5c5b3b5ffe27c8b3894d3d2bb 2034-03-11T04:58:57Z 2024-03-13T04:58:57Z
# 3. 创建Gateway和VirtualService
kubectl apply -f ingress-gwy.yaml -f ingress-virtualservice.yaml
# 使用istioctl查看网关路由
$ ./istioctl pc routes istio-ingressgateway-d4db74f5b-l44h4.istio-system
NAME VHOST NAME DOMAINS MATCH VIRTUAL SERVICE
http.8080 go-multiroute.default.svc.cluster.local:8080 go-multiroute.default.svc.cluster.local, *.foobar.com /* ingress-go-multiroute.default
backend * /healthz/ready*
backend * /stats/prometheus*
# 4.1 任何一个集群节点上进行HTTP访问
$ curl -H "Host: go-multiroute.default.svc.cluster.local" 20.1.185.158/route1
[v2] Hello, You are at /route1, Got: route1's content
$ curl -H "Host: x.foobar.com" 20.1.185.158/route1
[v2] Hello, You are at /route1, Got: route1's content
$ curl 20.1.185.158/route1 -w %{http_code}% # 不带匹配主机名的Host头部会被当做404处理
404
# 4.2 现在进行HTTPS访问
$ echo '20.1.185.158 go-multiroute.default.svc.cluster.local' >> /etc/hosts
$ echo '20.1.185.158 x.foobar.com' >> /etc/hosts
# -k 禁用客户端对服务器证书的检查(因为根证书没有对go-multiroute...这个地址生成过证书)
$ curl -k -H "Host: go-multiroute.default.svc.cluster.local" https://go-multiroute.default.svc.cluster.local/route1
[v2] Hello, You are at /route1, Got: route1's content
$ curl --cacert ./ca.crt https://x.foobar.com/route1
[v2] Hello, You are at /route1, Got: route1's content演示完成。下面我们简单看一下网关的一些运行时信息:
# listener是当前网关Pod(Envoy)运行时监听的端口以及对应服务。这里前两行就是我们刚才的配置
$ ./istioctl pc listener istio-ingressgateway-d4db74f5b-l44h4.istio-system
ADDRESSES PORT MATCH DESTINATION
0.0.0.0 8080 ALL Route: http.8080
0.0.0.0 8443 SNI: *.foobar.com,go-multiroute.default.svc.cluster.local Route: https.8443.https.ingress-go-multiroute.default
0.0.0.0 15021 ALL Inline Route: /healthz/ready*
0.0.0.0 15090 ALL Inline Route: /stats/prometheus*
# routes是当前网关Pod(Envoy)运行时维护的路由规则,这里可以看到我们刚才配置的两条规则
# - 注意观察【VIRTUAL SERVICE】列,该列非404即说明网关内配置的目标成功匹配到了定义的虚拟路由!
$ ./istioctl pc routes istio-ingressgateway-d4db74f5b-l44h4.istio-system
NAME VHOST NAME DOMAINS MATCH VIRTUAL SERVICE
http.8080 go-multiroute.default.svc.cluster.local:8080 go-multiroute.default.svc.cluster.local, *.foobar.com /* ingress-go-multiroute.default
https.8443.https.ingress-go-multiroute.default go-multiroute.default.svc.cluster.local:8443 go-multiroute.default.svc.cluster.local, *.foobar.com /* ingress-go-multiroute.default
backend * /healthz/ready*
backend * /stats/prometheus*
# clusters是当前网关Pod(Envoy)运行时维护的后端(envoy中称为cluster)列表
$ ./istioctl pc clusters istio-ingressgateway-d4db74f5b-l44h4.istio-system
SERVICE FQDN PORT SUBSET DIRECTION TYPE DESTINATION RULE
BlackHoleCluster - - - STATIC
agent - - - STATIC
go-multiroute.default.svc.cluster.local 3000 - outbound EDS
istio-ingressgateway.istio-system.svc.cluster.local 80 - outbound EDS
istio-ingressgateway.istio-system.svc.cluster.local 443 - outbound EDS
istio-ingressgateway.istio-system.svc.cluster.local 15021 - outbound EDS
istiod.istio-system.svc.cluster.local 443 - outbound EDS
istiod.istio-system.svc.cluster.local 15010 - outbound EDS
istiod.istio-system.svc.cluster.local 15012 - outbound EDS
istiod.istio-system.svc.cluster.local 15014 - outbound EDS
kube-dns.kube-system.svc.cluster.local 53 - outbound EDS
kube-dns.kube-system.svc.cluster.local 9153 - outbound EDS
kubernetes.default.svc.cluster.local 443 - outbound EDS
prometheus_stats - - - STATIC
sds-grpc - - - STATIC
xds-grpc - - - STATIC
zipkin - - - STRICT_DNS
# endpoint是网关Pod(Envoy)运行时维护的cluster背后的所有端点健康状态(比如一个service后面可能有几个pod,就都会展示在这里)
$ ./istioctl pc endpoint istio-ingressgateway-d4db74f5b-l44h4.istio-system
ENDPOINT STATUS OUTLIER CHECK CLUSTER
127.0.0.1:15000 HEALTHY OK prometheus_stats
127.0.0.1:15020 HEALTHY OK agent
192.168.31.2:6443 HEALTHY OK outbound|443||kubernetes.default.svc.cluster.local
20.2.36.83:53 HEALTHY OK outbound|53||kube-dns.kube-system.svc.cluster.local
20.2.36.83:9153 HEALTHY OK outbound|9153||kube-dns.kube-system.svc.cluster.local
20.2.36.86:8080 HEALTHY OK outbound|80||istio-ingressgateway.istio-system.svc.cluster.local
20.2.36.86:8443 HEALTHY OK outbound|443||istio-ingressgateway.istio-system.svc.cluster.local
20.2.36.86:15021 HEALTHY OK outbound|15021||istio-ingressgateway.istio-system.svc.cluster.local
20.2.36.89:3000 HEALTHY OK outbound|3000||go-multiroute.default.svc.cluster.local
20.2.36.90:53 HEALTHY OK outbound|53||kube-dns.kube-system.svc.cluster.local
20.2.36.90:9153 HEALTHY OK outbound|9153||kube-dns.kube-system.svc.cluster.local
20.2.36.91:15010 HEALTHY OK outbound|15010||istiod.istio-system.svc.cluster.local
20.2.36.91:15012 HEALTHY OK outbound|15012||istiod.istio-system.svc.cluster.local
20.2.36.91:15014 HEALTHY OK outbound|15014||istiod.istio-system.svc.cluster.local
20.2.36.91:15017 HEALTHY OK outbound|443||istiod.istio-system.svc.cluster.local
unix://./etc/istio/proxy/XDS HEALTHY OK xds-grpc
unix://./var/run/secrets/workload-spiffe-uds/socket HEALTHY OK sds-grpc
# 它们都可以通过一些参数进行过滤
$ ./istioctl pc endpoint istio-ingressgateway-d4db74f5b-l44h4.istio-system --port 3000
ENDPOINT STATUS OUTLIER CHECK CLUSTER
20.2.36.92:3000 HEALTHY OK outbound|3000||go-multiroute.default.svc.cluster.local
20.2.36.94:3000 HEALTHY OK outbound|3000||go-multiroute.default.svc.cluster.local[!WARNING] 删除包含证书的 secret 并不会影响网关继续正常响应对应证书域名的请求,这是因为网关不会处理删除证书的操作, 除非网关重启重新加载这些数据。所以要删除一个对外的服务端口,我们必须删除对应的 Gateway 配置。
此外,在部署验证过程中,观察网关 Pod 的日志可以确认网关是否成功加载了新配置。
清理
kubectl delete -f ingress-virtualservice.yaml -f ingress-gwy.yaml扩展主题
8.4.5.7 流量管理之访问外部服务
Ingress 网关控制的是外部流量如何进入网格,但网格如何访问外部服务呢?目前的默认做法是 sidecar 没有针对未知目标服务的流量代理做出任何限制, 比如应用容器可以直接访问类似www.google.com的外部域名或 IP,这种不受控的对外访问会带来安全风险, 尤其在某些组织要求对所有对外流量进行加密时。
Istio 提供了三种方式来解决这个问题:
- 配置 sidecar 代理拒绝调用未知的目标服务
- 配置 ServiceEntry 来声明外部服务,然后就可以通过 VirtualService 和 DestinationRule 来控制网格如何访问外部服务
- 对于特定 IP 范围的目标服务,配置 Istio 使应用容器绕过 sidecar 代理
本节内容主要参考自Istio:访问外部服务,其中第一种和第三种方式操作起来都很简单,所以本节演示仅限于第二种方式, 读者可以结合本节演示和官文加深对 ServiceEntry 的理解。
本节演示将实现如果通过 ServiceEntry+VirtualService 的方式来管理网格如何访问外部的一个专用于 HTTP 测试的网站httpbin.org, 所使用的清单是 external-access-control.yaml, 演示步骤如下:
# 部署两种对象
$ kubectl apply -f external-access-control.yaml
serviceentry.networking.istio.io/httpbin created
virtualservice.networking.istio.io/httpbin created
# 验证一:根路由重定向到 /ip (-L跟随跳转)
$ kubectl exec -it istio-client-test-$POD_ID -- curl -L httpbin.org
{
"origin": "119.x.198.51"
}
# 验证二:设置超时2s,要求延时3s返回(预期超时)
$ kubectl exec -it istio-client-test-$POD_ID -- curl httpbin.org/delay/3 -I
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
date: Mon, 18 Mar 2024 09:59:12 GMT
server: envoy
# 验证三:设置超时2s,要求延时1s返回(预期正常200)
$ kubectl exec -it istio-client-test-$POD_ID -- curl httpbin.org/delay/1 -I
HTTP/1.1 200 OK
date: Tue, 19 Mar 2024 13:29:55 GMT
content-type: application/json
content-length: 1473
server: envoy
access-control-allow-origin: *
access-control-allow-credentials: true
x-envoy-upstream-service-time: 1557理解原理
创建 Istio ServiceEntry 对象可以帮助我们将一个外部的域名注册到 Istio sidecar 中,之后就可以在 VirtualService 中引用该域名并编写路由规则。 若没有注册外部服务就直接引入外部 Host 到路由策略中,创建对象不会报错,但是应用在访问时会得到 503 的状态码结果。
ServiceEntry 对象支持为指定 Host 声明多个 IP 地址以及分别为每个 IP 指定端口,免去了 DNS 查询的步骤,方便管理仅通过 IP 公开的外部服务, 具体请参考其编写规范。
8.4.5.8 流量管理之 Egress 网关
Ingress 网关和 Egress 网关共同实现了网格网络的东西向流量控制。但相比 Ingress 而言,Egress 网关并不算常用, 因为大部分系统并不会要求对出口流量做控制,除非是一些特殊的、对网络出站安全有特别管控的系统。 也是由于 sidecar 的存在,Istio 可以很轻松的实现对出站流量的管控。这里的管控包含以下功能:
- 针对指定域名的出站流量的流量管理(熔断/超时等)
- 针对指定域名的出站流量的加密(TLS)
- 例如某些项目不允许服务器对外发起 HTTP 访问,所以当 app 发起 HTTP 请求时,请求到达 Egress 网关后,Egress 网关将按策略对 HTTPS 请求进行拦截。
- 统一监控并记录网格服务的出站流量(在 Egress 网关处查询即可)
[!NOTE] K8s 虽然没有提出 Egress 网关的概念,但提供了 NetworkPolicy 来控制 Egress 流量,其原理是通过 CNI 网络插件来实现的(部分功能需要安装的 CNI 插件支持), 但所提供的功能丰富性无法与 Istio 相提并论。
此外,Istio 还提及了 Egress 网关的另一个使用场景:“集群中的应用节点没有公有 IP,所以在该节点上运行的网格 Service 无法访问互联网。通过定义 Egress gateway,将公有 IP 分配给 Egress Gateway 节点,用它引导所有的出站流量,可以使应用节点以受控的方式访问外部服务。”
安装 Egress 网关
安装 Egress 网关,同时开启 sidecar 的访问日志。
# 修改 iop 配置文件 iop.yaml
# 此命令会更改已安装的名称为istio的configmap,并向网格中所有的Envoy实例注入新的配置。
#spec:
# components:
# egressGateways:
# - enabled: true
# name: istio-egressgateway
# ...
# meshConfig:
# ...
# accessLogFile: /dev/stdout
# accessLogEncoding: JSON
# 再次安装istio
$ ./istioctl install -f iop.yaml
# 查看已安装的egress网关
$ kubectl get deploy,svc -n istio-system |grep egress -B 1
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/istio-egressgateway 1/1 1 1 4m58s
--
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/istio-egressgateway ClusterIP 20.1.68.34 <none> 80/TCP,443/TCP 4m58s
# 查询sidecar的访问日志
$ kubectl exec -it istio-client-test-$POD_ID -- curl go-multiroute:3000/route1
[v2] Hello, You are at /route1, Got: route1's content
# 简单分析一下客户端sidecar的访问日志
# ①upstream是指sidecar代理的服务(也是转发目标),即sidecar1与sidecar2(远端节点)之间的连接
# client-app <---> sidecar1 -----------> sidecar2 <---> server-app
# upstream_local_address -- sidecar1与sidecar2连接时的ip:port
# upstream_host -- sidecar2的ip:port
# upstream_cluster -- sidecar2的DNS信息
# ②downstream是指sidecar接收流量的客户端,即sidecar1与client-app(近端节点)之间的连接
# client-app <---> sidecar1 -----------> sidecar2 <---> server-app
# downstream_remote_address:client-app的ip:port(与downstream_local_address建立连接)
# downstream_local_address:sidecar1的ip:port
# 其他还有response_code、route、duration、request_id、bytes_sent等有用信息。
$ kubectl logs -l app=istio-client-test -c istio-proxy --tail 1
{"upstream_transport_failure_reason":null,"protocol":"HTTP/1.1","user_agent":"curl/7.59.0","route_name":"default",
"response_code":200,"upstream_local_address":"20.2.36.96:39984","connection_termination_details":null,
"request_id":"5877d0cb-bd2b-4aa6-83c1-dd2e7dbf01be","response_flags":"-","upstream_host":"20.2.36.94:3000",
"bytes_sent":53,"x_forwarded_for":null,"upstream_cluster":"outbound|3000||go-multiroute.default.svc.cluster.local",
"authority":"go-multiroute:3000","start_time":"2024-03-17T16:42:07.449Z","method":"GET",
"response_code_details":"via_upstream","downstream_local_address":"20.1.207.122:3000","requested_server_name":null,
"duration":2,"upstream_service_time":"2","downstream_remote_address":"20.2.36.96:46218","path":"/route1","bytes_received":0}
# 此外,你还可以查看服务端istio-proxy的日志,并自行分析获得更清晰的访问记录认识。sidecar 默认的日志级别是 Info,有时候可能需要为特定负载设置 Debug 级别日志,以便进行网络故障排查。可通过下面的方式设置:
# 方式一
kubectl exec {POD-NAME} -c istio-proxy -- curl -X POST http://127.0.0.1:15000/logging?level=debug
# 方式二
./istioctl pc log <POD-NAME>.[NAMESPACE] --level debug本节演示包含两部分:
- 演示一:Egress 网关透明转发 HTTP 请求(HTTP->HTTP)
- 演示二:Egress 网关透明转发 HTTPS 请求(HTTPS->HTTPS)
- 演示三:Egress 网关将 HTTP 请求转换为 HTTPS 请求(HTTP->HTTPS)
演示四:Egress 网关将 HTTPS 请求转换为 HTTP 请求(HTTPS->HTTP)没有这种要求
演示一:Egress 网关透明转发 HTTP 请求(HTTP->HTTP)
# 部署策略
$ kubectl apply -f egressgwy-proxy-http2http.yaml
serviceentry.networking.istio.io/istio-io created
gateway.networking.istio.io/egress-istio-io created
virtualservice.networking.istio.io/egressgateway-proxy-http-istio-io created
# 验证:在注入sidecar的客户端容器中访问注册的外部服务(预期:HTTP访问应该返回301)
$ kubectl exec -it istio-client-test-668bb6fc86-mmqf9 -- curl istio.io -I
HTTP/1.1 301 Moved Permanently
content-type: text/plain; charset=utf-8
date: Wed, 20 Mar 2024 04:12:07 GMT
location: https://istio.io/
server: envoy
x-nf-request-id: 01HSD0YB5MSPEPC1Y5R85AMREM
x-envoy-upstream-service-time: 387
transfer-encoding: chunked
# 验证:查询egress网关日志,确认流量通过网关转发(根据 upstream_cluster 和 response_code 字段判断)
# - 在部署策略前,egress网关不会出现这条访问日志
# - 网关中的 upstream 是指自己所代理的服务,而egress代理的是外部服务;
$ kubectl logs -l istio=egressgateway -nistio-system --tail 2
{"requested_server_name":null,"authority":"istio.io","upstream_service_time":"376","path":"/","downstream_remote_address":"20.2.36.112:42936",
"x_forwarded_for":"20.2.36.112","upstream_local_address":"20.2.36.108:52900","downstream_local_address":"20.2.36.108:8080",
"duration":377,"bytes_sent":32,"upstream_transport_failure_reason":null,"response_code_details":"via_upstream",
"response_flags":"-","request_id":"252fce5c-0a92-99c2-93cd-4ce7ba0bd995","connection_termination_details":null,
"response_code":301,"upstream_cluster":"outbound|80||istio.io","start_time":"2024-03-18T16:52:08.157Z","bytes_received":0,
"upstream_host":"75.2.60.5:80","method":"GET","user_agent":"curl/7.59.0","route_name":null,"protocol":"HTTP/2"}
2024-03-18T16:35:39.362022Z info xdsproxy connected to upstream XDS server: istiod.istio-system.svc:15012
# 清理
$ kubectl delete -f egressgwy-proxy-http2http.yaml演示二:Egress 网关透明转发 HTTPS 请求(HTTPS->HTTPS)
# 部署策略
$ kubectl apply -f egressgwy-proxy-https2https.yaml
serviceentry.networking.istio.io/istio-io-https created
gateway.networking.istio.io/egress-istio-io-https created
virtualservice.networking.istio.io/egressgateway-proxy-https-istio-io created
# 验证:查询egress网关日志,确认流量通过网关转发(根据 upstream_cluster 和 response_code 字段判断)
# - 在部署策略前,egress网关不会出现这条访问日志
$ kubectl logs -l istio=egressgateway -nistio-system --tail 1
{"upstream_local_address":"20.2.36.108:35544","duration":961,"requested_server_name":"istio.io","protocol":null,"path":null,
"method":null,"bytes_received":454,"authority":null,"connection_termination_details":null,"response_flags":"-","bytes_sent":3204,
"start_time":"2024-03-18T17:33:45.987Z","user_agent":null,"upstream_transport_failure_reason":null,"upstream_cluster":"outbound|443||istio.io",
"response_code_details":null,"upstream_service_time":null,"route_name":null,"upstream_host":"75.2.60.5:443","response_code":0,
"downstream_local_address":"20.2.36.108:8443","request_id":null,"x_forwarded_for":null,"downstream_remote_address":"20.2.36.112:52658"}
# 清理
$ kubectl delete -f egressgwy-proxy-https2https.yaml演示三:Egress 网关将 HTTP 请求转换为 HTTPS 请求(HTTP->HTTPS)
# 部署策略
$ kk apply -f egressgwy-proxy-http2https.yaml
serviceentry.networking.istio.io/istio-io created
gateway.networking.istio.io/egress-istio-io-http2https created
destinationrule.networking.istio.io/egressgateway-for-istio-io created
virtualservice.networking.istio.io/egressgateway-proxy-istio-io-http2https created
destinationrule.networking.istio.io/originate-tls-for-istio-io created
# 验证:在客户端容器使用http协议访问host(预期会因为网关的转发而得到200响应)
# - 若没有网管的tls转发,则会得到301响应
$ kk exec -it istio-client-test-$POD_ID -- curl istio.io -I
HTTP/1.1 200 OK
...
# 清理
$ kubectl delete -f egressgwy-proxy-http2https.yaml这三个演示可以覆盖大部分 Egress 网关的使用场景。对于演示三,我们需要知道网关是以SIMPLE方式对istio.io发起 TLS 连接, 这表示作为客户端的网关没有提供自己的证书给对方主机,因此存在第四个场景就是:网关与对方主机之间建立 mTLS 连接。 这个场景比较少见,它首先要求对方主机需要验证客户端证书,否则提供也没意义;如有兴趣,请参考官方提供的 Egress 网关发起的 mTLS 演示。
必要的安全措施
请注意,Istio 无法做到让集群中的所有出站流量都经过 Egress 网关转发,所以存在集群服务绕过 Egress 网关直接访问外部服务 的可能, 这些服务的外站访问能够完全脱离 Istio 的控制和监控。
如果你不希望集群中有任何 Pod 的出站流量能够绕过 Egress 网关(脱离 Istio 的控制和监控), 建议你部署 K8s 的 NetworkPolicy 来保证仅允许来自 Egress 网关的流量可以通过集群边缘, 具体请参考Istio Egress 安全事项。
仅允许访问已注册的服务
如果你希望控制网格内的服务仅能访问已在网格或集群中注册的服务,那你可以通过修改 IstioOperator 配置文件来完成。执行命令: istioctl install -f iop.yaml --set meshConfig.outboundTrafficPolicy.mode=REGISTRY_ONLY,默认的 mode 配置是ALLOW_ANY,即允许访问任何域名,而REGISTRY_ONLY表示仅允许访问已注册的服务。更改配置后,等待几秒钟生效, 然后你就会发现网格内的服务无法访问类似baidu.com这样的外部地址了,因为它没有在网格内进行注册, 通过 ServiceEntry 对象完成网格内的服务注册就可以正常访问了。
最后,如果你在配置 TLS 时感到困惑,可以阅读官网文档 理解 TLS 配置。
8.4.5.9 其他示例
- 你可以将网格中的出站流量通过 ServiceEntry 引导至其他专用代理(而不是 Egress 网关),然后由专用代理负责控制和转发流量;
- 上一节中的演示案例都是针对单一域名的引导配置,你也可以为一个泛域名创建 ServiceEntry 和 Gateway 等对象
- 流量镜像:你可以配置将访问某个 Host 的流量按百分比复制到其他目标,这可以助你实现实施流量分析和安全审计;
- 速率限制:你可以为 ingress 网关和 sidecar 配置速率限制,以限制访问某个 Host 的流量速率;
此外,还有可观测性相关的更多示例,请参考Istio 可观测性。
8.4.6 故障处理
故障一:配置下发失败
故障体现为应用容器没有安装配置的路由策略执行,通过istioctl pc route ...无法看到最新的路由策略。 此外观察 istiod 日志发现大量error级别的日志。
$ kubectl logs -l app=istiod -nistio-system --tail 5
2024-03-18T15:28:07.316091Z error security Failed to authenticate client from 20.2.36.105:40058:
Authenticator ClientCertAuthenticator: no verified chain is found; Authenticator KubeJWTAuthenticator:
failed to validate the JWT from cluster "Kubernetes": the service account authentication returns an error:
[invalid bearer token, service account token has expired]
...重复具体原理笔者还未查明,但已经查到的问题是运行 app 容器的节点与 K8s 集群主节点时间不同步(相差好几个小时), 同步后无需操作集群,修复后的几秒内 istiod 控制面会成功完成与 sidecar 的配置同步。
[!Important] 配置不同步可能会影响网格内服务的正常访问(导致 503),这是因为 sidecar 的 Endpoints 列表是从 Istio 控制面(xDS 中的 EDS)获取的。 你可以通过命令
istioctl pc route/cluster/endpoint $POD来逐步排查原因。
关于流量管理配置相关的故障,请参考官方文档流量管理问题。
8.4.7 Istio 服务的健康检查
Istio 需要对 APP 容器的部分类型的存活及就绪探针规则进行重写,以使它们能够正常工作。这是因为:
- 对于 HTTP 类型的探针:kubelet 负责向应用发送探测请求。但在启用 Istio mTLS 的情况下,由于 kubelet 没有 Istio 颁发的证书,因此健康检查会失败;
- 对于 TCP 类型的探针:kubelet 仅检查 Pod 某端口是否开放。但在注入 Istio sidecar 的情况下, Pod 已经被
istio-init初始化容器所添加的 iptables 规则将从任意端口流入 Pod 的流量转发到 sidecar 处理,因为从外部探测 Pod 的任意 TCP 端口都会成功;iptables -t nat -A PREROUTING -p tcp -j REDIRECT --to-port 15001是一条示例 iptables 规则(实际会稍复杂点), 它将所有进入 Pod 的 TCP 流量转发到 sidecar 的 15001 端口,即只要 sidecar 容器的 15001 端口正常监听,则外部对 Pod 的任意 TCP 端口探测都会成功。
其他类型的探针如 Shell 命令、gRPC 类型的探针则不会被重写。当工作负载部署后,你可以查看其描述来了解重写后的规则。 当然,若你不希望为全局开启默认重写或想要为特定负载关闭规则重写行为,Istio 也提供了对应的方法,具体操作较为简单, 请参考官方文档 Istio 健康检查。
8.4.8 协议选择
首先,Istio 提供的 sidecar 代理支持原始 TCP 和基于 TCP 的 HTTP 系列协议以及 gRPC 协议。Istio 注入的 sidecar 不会代理 UDP 协议, 外部流量将直接到达 APP 容器而不会由 sidecar 转发。
Istio 还实验性的对 mongo、redis、mysql 协议进行支持。
显式的为 Service 指定协议类型
当我们为应用定义 K8s Service 对象时,通常按照下面的模板定义:
...
spec:
type: ClusterIP
selector:
...
ports:
- name: custom-name
port: 80
targetPort: 80然而这种定义方式存在一个问题,那就是没有指定协议类型(K8s 可能不需要,但 Istio 需要)。Istio 仅支持对 HTTP/HTTP2 流量的识别, 对于其他 TCP 流量,统一当做不透明的原始 TCP 流量进入路由规则(VirtualService)匹配。此时,如果你提前为 HTTPS 流量定义了tls 类型的路由规则,那么很遗憾,这条规则不会生效,sidecar 将按照默认方式转发流量,除了路由规则,一些高级流量策略(DestinationRule)也都将形同虚设。
因此,最好显式的为 Service 指定协议类型,Istio 支持两种识别方式:
- Service 中的
ports.name命名格式为<protocol>[-<suffix>],例如http或http-xxx;- 不建议。因为与 sidecar 不同,当 Service 作为 Ingress 网关的后端时,网关无法根据
ports.name来识别协议类型,因此建议都使用第二种。
- 不建议。因为与 sidecar 不同,当 Service 作为 Ingress 网关的后端时,网关无法根据
- 在版本 v1.18+ 的 Kubernetes,通过
ports.appProtocol字段配置协议(优先于第一种)。
备注:本节内容是对官方文档 Istio 协议选择 更深度的解读与补充。
8.4.9 流量路由详细过程
假设现在已经定义了一个 VirtualService(下简称 VS) 和 DestinationRule(下简称 DR) 对象,下面基于此假设进行阐述。
在 Istio 的流量路由中,我们将整个过程分为两个阶段:
- 匹配前端:匹配待处理流量的协议类型
- Istio 将创建的上述路由规则写入 sidecar 容器(或网关),可通过
istioctl pc route $SIDE_CAR_POD_ID进行验证; - 当流量发送至 sidecar (或网关)时,后者根据 VS 中定义的流量协议进行匹配;
- 若定义了
http协议,则匹配 HTTP/HTTP2/gRPC 协议类型的流量(会检查Host头部 是否匹配,若是 gRPC 则检查:authority头部); - 若定义了
tls协议,则匹配 TLS 协议类型(包含 HTTPS 和 TCP over TLS)的流量(会在配置了tls.sniHosts的情况下检查SNI头部是否匹配,并且无法使用 path 和 header 相关的匹配条件); - 若定义了
tcp协议,则匹配原始 TCP 协议类型(包含以上所有协议)的流量(没有头部可供检查,但可以添加目标子网、端口或源负载标签的匹配条件);
- 若定义了
- 若 sidecar (或网关)没有匹配到配置中的流量协议,则按以下流程处理流量:
- 情况 1:若是 ingress 网关,则返回 404。若是 egress 网关,由于流量未到网关,则由 sidecar 自行处理(参照情况 2);
- 情况 2:若是 sidecar,则按本地路由表转发,目的地可能是网格内/外的服务,具体转发规则如下:
- 若是网格内服务,则可能使用 mTLS 进行转发(前提是配置了相应的 mTLS 策略);
- 其他情况则应该是统一当做不透明的 TCP 流量处理。
- Istio 将创建的上述路由规则写入 sidecar 容器(或网关),可通过
- 转发后端:决定以何种协议转发流量至后端
- 当 sidecar (或网关)成功匹配到流量协议后,会根据 VS 中定义的
route.destination进行转发,进入下一步; - 若 VS 中为转发后端还定义了
subset(那该后端一定是集群内定义的 Service),则查找 Host 对应的 DR 规则,根据 DR 规则中定义的subset进行转发(若找不到对应的subset则返回 404);- 转发时遵循 DR 中定义的
spec.trafficPolicy;
- 转发时遵循 DR 中定义的
- 若 VS 中没有定义
subset,则也查找 Host 对应的 DR 规则,根据 DR 规则中定义的spec.trafficPolicy进行转发;- 若没有对应的 DR 规则,则按本地路由表转发;
- 转发时需要决定使用何种协议类型:
- 若后端是集群内定义的 Service,则使用 Service 定义中的
ports[?].appProtocol或ports.name指示的协议; - 若后端是通过 Istio ServiceEntry 注册的外部服务,则使用 ServiceEntry 中定义的
ports[?].protocol指示的协议;
- 若后端是集群内定义的 Service,则使用 Service 定义中的
- 当 sidecar (或网关)成功匹配到流量协议后,会根据 VS 中定义的
关于 Headless Service
K8s 中的 Headless Service 是一种特殊的 Service,它没有 ClusterIP,而是通过 DNS 解析的方式,将 Service 的名称解析为一组 Pod 的 IP 地址。这种类型的 Service 作为 Istio 的转发后端时,Istio 要求它必须定义 ports字段,否则无法匹配。
8.4.10 保留客户端 IP
对于存在反向代理或网关的集群来说,在转发请求时保留客户端 IP 是一个常见且许多场景下必要的需求, Istio 允许通过配置以支持网关在转发时保留客户端 IP。具体来说,支持两种方式:
- 使用 IstioOperator 自定义资源去配置全局设置;
- 为入口网关 Pod 配置特定注解;
这包含对 HTTP 系列协议和 TCP 协议的支持,本节不演示具体操作,请直接参考官方文档。
下面展示的是通过修改 IOP 的配置来修改网格全局的 Envoy 代理配置(请先阅读官方文档):
# nonk8s
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
# ...
meshConfig:
defaultConfig:
proxyMetadata: { }
# 配置 sidecar 对 HTTP 请求和响应header的行为(增删改)
proxyHeaders:
# 对 XFCC 头的行为
forwardedClientCert: SANITIZE
# 配置 gateway 的部分代理行为
gatewayTopology:
numTrustedProxies: 0
forwardClientCertDetails: SANITIZE以 XFCC(即X-Forwarded-Client-Cert) 头为例:默认情况网关和 sidecar 都会传递 XFCC 头, 若网关将配置字段forward...改为SANITIZE,则 sidecar 仍然会传递 XFCC 头(并添加网关的身份 ID,但不会添加自己的身份 ID, 这可能是因为 sidecar 的转发目标是本地);若 sidecar 将配置字段forward...改为SANITIZE,则最终负载将无法收到 XFCC 头。
对于 XEEA(即X-Envoy-External-Address)头,笔者认为其实不需要去配置,因为 Istio 网关默认会通过 XFF 头保留客户端 IP, 所以只需要手动解析 XFF 头即可获取客户端 IP。而 XEEA 头仅在多个代理间传递时会存在。
8.4.11 最佳实践
8.4.11.1 流量管理
以下将 VirtualService 简称 VS,DestinationRule 简称 DR。
为每个 Service 配置默认路由
官方建议为刚开始部署每个 Service 的是时候就为其配置默认的路由规则,以便在 Service 需要使用灰度上线时可以简单修改规则以快速完成部署。 提供的清单示例:default_svc_route_rule.yaml
跨命名空间重用配置
你可以在一个命名空间中创建一个 VirtualService,DestinationRule 或 ServiceEntry,然后在另一个命名空间中引用它,以避免重复配置。 默认情况下,Istio 允许一个配置在所有空间下可用,但你可以通过设置exportTo来限制其可用范围(可限制到当前空间/指定空间/全部空间)。
将 DestinationRule 部署在服务所在空间
首先,DR 的生效是有一个规则的,例如 DR 部署在 default 空间(但对所有空间可见),然后 Service 在 ns1 空间,且发出请求的客户端在 ns2 空间,那么这个 DR 规则永远不会生效,这是因为 Istio 要求 DR 规则的查找路径是:客户端空间--> Service 所在空间 --> 根空间(istio-system)。
所以,我们在创建 DR 时最好在清单中就定义metadata.namespace与 Service 所在空间一致,以避免网格策略增长后产生一定的混乱。 之所以不放在根空间,是因为实际环境中并不一定每个人都被允许访问根空间。
将大型 VirtualService 和 DestinationRule 拆分为多个资源
就比如在 Ingress 网关关联的 VS 对象,通常会定义多个 HTTP 路由匹配规则。若这些规则都放在一个 VS 清单中,就会造成管理上的混乱, 因为这些规则对应的子集服务可能被部署在不同的命名空间中(可能由不同团队管理)。
所以,最好将这些规则拆分为多个清单(以 Service 为单位划分),以便于管理,它们在应用时会自动合并。 此外,若你的 VirtualService 规则中存在严格先后顺序的流量匹配规则, 则你只能将它们合并到一个清单中,因为拆分后无法保证先后顺序, 提供一个存在匹配规则重叠的示例:virtualservice-in-order.yaml。此外, 对于针对相同 Host 的多个 VS 策略,只有在绑定网关时,多个 VS 策略才能合并;当应用于 sidecar 时,多个 VS 策略是不支持合并的, 只有一个 VS 策略会生效(通过istioctl pc route $POD查看生效的策略), 示例清单:unmergeable-vs.yaml。
另外,对于 DR 对象,如果多个 DR 清单都应用于同一个 Host,则它的合并情况与 VR 对象不同。具体来说,对于同一个 Host:
- Istio 不支持合并多个清单中定义的同名子集(其他 DR 清单中命名重复的子集将被抛弃);
- 同一 Host 只能有一个
spec.trafficPolicy配置(其他 DR 清单中的同级策略将被抛弃)
按照顺序增删 VS 和 DR 对象
首先,我们应该明白,清单的生效是有延时的(从控制面传播到 sidecar)。当我们同时部署有关联的 VS 和 DR 清单时, 是有可能会出现客户端访问得到 503 的 HTTP 状态码。这是因为 VS 对象可能先于 DR 对象被传播到 sidecar,导致 VS 引用了不存在的 DR 子集。为了避免此类情况,我们需要将二者分离到不同清单,然后先部署 DR 对象,等待几秒后,再部署 VS 对象。 若要百分百确定 DR 对象的生效,可使用命令:istioctl pc cluster $POD。
反过来,按照先 VS 再 DR 的顺序进行删除(解除引用)。
8.4.11.2 安全
认证和授权是 Istio 的两项重要安全特性,你应该在安装 Istio 之后尽快部署对应策略。 参照 Istio 特性之 mTLS 小节末尾的建议逐步将网格服务迁移至双向 TLS, 然后再根据需要添加授权策略。
对于授权策略,我们应当遵循 default-deny 授权策略模式,参照清单:authz-allow-nothing.yaml。 此外,官方建议使用 ALLOW-with-positive-matching 和 DENY-with-negative-match 模式, 参考官方提供的示例清单:authz-recommend.yaml
规范 HTTP 路径
默认情况下,Ingress 网关或 sidecar 会对收到的 HTTP(s)请求进行路由规范化,比如将 /a/../b 规范为 /b。 \da 规范为 /da,规范化是为了确定在流量策略中进行路径相关的匹配行为,当然还有授权策略。
你可以通过 IOP 配置来定义网格代理对 HTTP 路径的规范化力度:
# iop.yaml
# 参考:https://istio.io/latest/zh/docs/reference/config/istio.mesh.v1alpha1/#MeshConfig-ProxyPathNormalization-NormalizationType
spec:
meshConfig:
pathNormalization:
normalization: DEFAULT # DEFAULT, NONE, BASE, MERGE_SLASHES, DECODE_AND_MERGE_SLASHES此外,Envoy 文档表示这种规范化设置不会处理路径中的大小写字母。 参考 官方文档 了解更多。
[!NOTE] 对 HTTP 路径的规范化会修改客户端发送的请求,即最终服务端收到的 HTTP 路径与客户端发送的 HTTP 路径可能不会完全一致, 注意在上线前进行详尽的用例测试。
流量拦截的局限性
Istio 流量拦截的原理是通过 sidecar 进行,而且仅拦截基于 TCP 协议的流量。此外,sidecar 设置是属于 Pod 粒度, 所以用户可能移除拦截规则,或者移除、修改或替换 sidecar 容器。这会导致 Istio 的各种流量和安全策略彻底失效。
为了进一步确保流量安全,你可以使用 K8s 内置的 NetworkPolicy API 来定义网络策略。例如, 仅允许携带标签app: backend的负载访问app: mysql负载的 3306 端口。
确保 Egress 流量安全
正如上面所说,Istio 无法强制 Egress 流量都经过 Egress 网关,所以你需要使用 NetworkPolicy API 来保证这一点。 部署 Egress 网关后,建议修改 Istio 配置 outboundTrafficPolicy.mode=REGISTRY_ONLY 来阻止访问未注册的服务。
其他还有一些安全最佳实践,在此不再一一列出,请参考官方提供的 Istio 安全最佳实践。
8.4.12 Dashboard
Istio 支持集成第三方 Web 控制台来查看和管理内部配置以及运行状态。通过 istioctl 命令可查 istio 支持的控制台类型。
$ istioctl dashboard -h
Access to Istio web UIs
...
Available Commands:
controlz Open ControlZ web UI
envoy Open Envoy admin web UI
grafana Open Grafana web UI
jaeger Open Jaeger web UI
kiali Open Kiali web UI
prometheus Open Prometheus web UI
proxy Open admin web UI for a proxy
skywalking Open SkyWalking UI
zipkin Open Zipkin web UI但是,这些控制台不是 Istio 默认安装的一部分,需要用户手动安装。其中 kiali 是 Istio 的主控制台,它可以实时监控网格服务的结构和运行状态, 并允许在 Web 控制台进行配置,是官方推荐安装的控制台,具体安装方法请参考官方文档。kiali 控制台的安装和使用都很简单, 此处不再赘述。其他控制台则根据需求进行安装即可,官方也都有提供相应的安装文档。
8.4.13 扩展—注入的 iptables 规则
通过以下命令获得任何一个网格服务的 iptables 规则(它们是一致的):
kubectl debug $POD_ID -it --image vimagick/iptables --profile=netadmin -- iptables -tnat -S规则列表如下:
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N ISTIO_INBOUND
-N ISTIO_IN_REDIRECT
-N ISTIO_OUTPUT
-N ISTIO_REDIRECT
-A PREROUTING -p tcp -j ISTIO_INBOUND
-A OUTPUT -p tcp -j ISTIO_OUTPUT
-A ISTIO_INBOUND -p tcp -m tcp --dport 15008 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15090 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15021 -j RETURN
-A ISTIO_INBOUND -p tcp -m tcp --dport 15020 -j RETURN
-A ISTIO_INBOUND -p tcp -j ISTIO_IN_REDIRECT
-A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006
# ---- ISTIO_OUTPUT 链拥有最复杂的规则 ----
# -- 对于来自`127.0.0.6/32`且出口网卡是本地环回口的流量,直接跳出当前链(不应用链中后续规则);
# -- `127.0.0.6`和`lo`分别是sidecar转发流量至应用容器时(也是生效时机)的通信地址及网卡;
# -- 这条规则有效避免了sidecar转发给应用容器的流量被重定向至自身,导致死循环;
-A ISTIO_OUTPUT -s 127.0.0.6/32 -o lo -j RETURN
# -- 对于sidecar发出的站内流量,重定向到 ISTIO_IN_REDIRECT 链(再次进入sidecar)
# -- 1337 是sidecar的固定 UID 和 GID;
# -- 此规则用于sidecar发起(使用127.0.0.6)的自身服务调用(其本身就启动了多个服务,监听了多个15xxx端口)
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --uid-owner 1337 -j ISTIO_IN_REDIRECT
# -- 对于Pod内除sidecar以外容器发出的站内流量,跳出当前链,直达目的地
# -- 此规则用于Pod内除sidecar以外容器之间(或与自身端口)的通信;
-A ISTIO_OUTPUT -o lo -m owner ! --uid-owner 1337 -j RETURN
# -- 对sidecar发出的其他流量,跳出当前链,直达目的地
-A ISTIO_OUTPUT -m owner --uid-owner 1337 -j RETURN
# -- 同上三条,只是从UID扩大至GID
-A ISTIO_OUTPUT ! -d 127.0.0.1/32 -o lo -p tcp -m tcp ! --dport 15008 -m owner --gid-owner 1337 -j ISTIO_IN_REDIRECT
-A ISTIO_OUTPUT -o lo -m owner ! --gid-owner 1337 -j RETURN
-A ISTIO_OUTPUT -m owner --gid-owner 1337 -j RETURN
# -- 对于去往Pod内部(除sidecar外的容器)的流量,直接跳出当前链,直达目的地
# -- 此规则用于Pod内容器之间(或与自身端口)的通信,主要是指sidecar发给应用容器的流量;
-A ISTIO_OUTPUT -d 127.0.0.1/32 -j RETURN
# -- 这两条规则表示:将 ISTIO_OUTPUT 链捕获的流量转发至 ISTIO_REDIRECT,后者再将TCP流量转发至15001(sidecar出站)端口;
# -- sidecar 拥有入站和出站两个handler
# -- ISTIO_OUTPUT 链最终是将应用容器的出站流量转发至 sidecar 的出站handler;
-A ISTIO_OUTPUT -j ISTIO_REDIRECT
-A ISTIO_REDIRECT -p tcp -j REDIRECT --to-ports 15001你可以使用 AI 工具详细分析以上规则列表,这里笔者仅做总结性分析:
- 首先设置四条已知链的默认动作是放行;
- 然后新建四条
ISTIO_*链,并随后为这些链添加规则;- ①:
-A PREROUTING -p tcp -j ISTIO_INBOUND- PREROUTING 链增加规则:路由后的 TCP 数据包直接转发至
ISTIO_INBOUND链;
- PREROUTING 链增加规则:路由后的 TCP 数据包直接转发至
- ②:
-A ISTIO_INBOUND ... --dport 150xx -j RETURN(四条)- ISTIO_INBOUND 链增加规则:对于进入
ISTIO_INBOUND链的数据包,如果目的端口是150xxx,则直接跳出当前链(直接进入OUTPUT链而不是自定义链); 150xx端口是 sidecar 自身占用的端口,用于与 istio 控制面通信以及自身健康检查用途, 参考 Istio 使用端口;
- ISTIO_INBOUND 链增加规则:对于进入
- ③:
-A ISTIO_INBOUND -p tcp -j ISTIO_IN_REDIRECT- ISTIO_INBOUND 链增加规则:将其他(除了
150xxx以外的)TCP 数据包转发至ISTIO_IN_REDIRECT链;
- ISTIO_INBOUND 链增加规则:将其他(除了
- ④:
-A ISTIO_IN_REDIRECT -p tcp -j REDIRECT --to-ports 15006- ISTIO_IN_REDIRECT 链增加规则(关键):将
ISTIO_IN_REDIRECT链中的 TCP 数据包重定向至 15006 端口(sidecar 入站端口); - 结合规则③,含义是将除了原本目标是进入 sidecar 以外的 TCP 数据包重定向至 sidecar 代理;
- ISTIO_IN_REDIRECT 链增加规则(关键):将
- 对于 ISTIO_OUTPUT 链内的规则,在上面通过注释已经说明。
- ①:
汇总可知:
- ISTIO_IN_REDIRECT 链用于捕获 Pod 的入站流量,然后转发至 sidecar 的入站端口(15006);
- ISTIO_REDIRECT 链用于捕获 Pod 的出站流量,然后转发至 sidecar 的出站端口(15001);
最后,根据以上规则我们还能推断出,对于 Pod 而言,并不是全部的流量都会被拦截:
- 转发只针对基于 TCP 的流量。任何 UDP 或其他网络层协议(如 ICMP、ARP 等)包不会被拦截或更改;
- 不会拦截 sidecar 自身使用的端口(
15xxx)以及 22 端口;
此外,Istio 允许我们扩展需要排除的出入站拦截端口:
- 通过为负载添加
traffic.sidecar.istio.io/excludeInboundPorts注解扩展需要排除的入站拦截端口; - 通过为负载添加
traffic.sidecar.istio.io/excludeOutboundPorts注解扩展需要排除的出站拦截端口;
8.4.14 扩展—Envoy 之坑
TODO
8.4.15 常用命令集合
部署前:
# 部署前诊断YAML配置是否正确,参数可以是目录、或通配符如 *.yaml
istioctl analyze a.yaml
# 直接诊断集群(获得建议和问题报告)
istioctl analyze -A
# 查看添加注入标签的NS(标签的值可以是 enabled 或 disabled)
kubectl get namespace -l istio-injection部署后:
# 检查pod是否被正确注入了sidecar,以及原因
# - 最后一个参数可以替换为:deploy/<deployment-name> 或 -l <label-key>=<label-value>
istioctl experimental check-inject -n <namespace> <pod-name>
# 查看pod内sidecar使用的istio证书信息
istioctl proxy-config secret <pod-name[.namespace]>
# 查看pod实时的路由、集群和端点信息(添加-o json获得更详细的信息)
# 如何调试envoy:https://istio.io/latest/zh/docs/ops/diagnostic-tools/proxy-cmd/
istioctl pc listener|route|cluster|endpoint <pod-name[.ns]> [flags]
# 查看端口3000的端点的详细信息(包含健康信息)
istioctl pc endpoint <pod-name[.ns]> --port 3000 -ojson
# 查看网格中所有pod的istio配置的同步状态(NOT SENT表示没有可发送的内容)
istioctl ps
# 查看pod的istio配置的同步状态
istioctl ps <pod-name[.ns]>
# 查看pod的授权策略信息
istioctl x authz check <pod-name>
# 查看注入了sidecar的网格服务与istio控制面的xDS同步状态
istioctl ps
# 查看svc或pod关联的istio资源配置(如 DR、VS、PeerAuthentication、Gateway等)
# - 并且会输出VS和DR配置中存在的问题
istioctl x describe <svc|pod> <name>
# 检查集群中的Istio配置是否存在问题
istioctl analyze -A
# 测试pod与istiod pod的连通性,进入pod内执行(正常能够获得istiod版本信息)
curl -sS istiod.istio-system:15014/version
# 查看sidecar(即envoy)版本,进入sidecar容器执行
# - 返回示例: { "version": "2d4ec97f3ac7b3256d060e1bb8aa6c415f5cef63/1.17.0/Clean/RELEASE/BoringSSL" }
pilot-agent request GET server_info --log_as_json | jq {version}其他:
# 其中 app=productpage 是工作负载的标签
# 查询 sidecar 从控制面拉取的授权配置(验证实际分发的配置)
kubectl exec $(kubectl get pods -l app=productpage -o jsonpath='{.items[0].metadata.name}') -c istio-proxy -- pilot-agent request GET config_dump
# 设置istio控制面pod的日志级别,用于调试
istioctl admin log --level ads:debug,authorization:debug